��ˮƽ���о����ܴ�����ṹ�ϲ������������������ṹ��������Ϊ��������ʺͿ����ٴ���Ԥ��ʩ����Ҫ�Ⱦ�������������о������˹������ӵ�"ָ��ʶ��"������ȷ�����Ե��������������ڴˣ����ǿ�����һ��������Ϊ���ĵĹ�������ģ�͵IJ��䷽������ģ��ע�����ߵĹ�ͬ��������������չʾ������ڽڵ㹦�����ӣ�nFC����ȫ�����߹������ӣ�eFC����һ���Ƚ���������eFC�ڲ�ͬ�����ݼ��ͷ����е�ʶ��������ǿ����������ڲ�ͬ�ռ�߶��ϣ��ӵ����ڵ㵽����ϵͳ�ͼ�Ⱥˮƽ��ʹ��k-means��������������˱��Ե�ʶ������������ʹ�õ�k-means���������������ij��÷��������ڲ�ͬ�Ŀռ�߶��ϣ����Ƿ��ֶ�ģ̬�����ȵ�ģ̬���о��˶��ͱ�Ե������������ֳ�һ�¸�ǿ��ʶ��������������Ƿ���ͨ��ʹ�����ɷֵ��ض��Ӽ����ؽ�eFC���Խ�һ�����ʶ����������֮�����ǵ��о����֤����������Ϊ���ĵ�����ģ�Ϳ����ڲ�������ĸ�����������������Ϊ���ʹ��eFCģ��ʶ��������춨�˻��������ķ�����Neuroimage��־��(�������ź�siyingyxf��18983979082��ȡԭ�ģ���˼Ӱ�ṩ����������ط�������ҪҲ�����Ӵ��ź���Ⱥ��ԭ��Ҳ����Ⱥ���)��
�ɽ�������������������Ķ�������������˼Ӱ���ṩ��ط�����������Ҫ�����siyingyxf��18983979082��ѯ����
������Ϊ���ĵ��������Ƥ�㹦�������ʾ���ص���ϵͳ��νṹ
1 ����
�ڹ�ȥ�ļ�ʮ�����Ӱ��ѧ�����Ѿ�����ǿ��ļ��㷽������������Դ�����̬���ܵı�����Ⱥ������ָ�꣨Toga, Evans, 1998������ǿ�����Ƕ���֪�����Է����Լ�������Fornito���ˣ�2015���Ĺ��ܺ�����ѧ��������ʶ��Ȼ������Щ�о�ǿ������ˮƽЧӦ���������˴�����֯�ĸ��Ի�����������
�����һЩ��Ҫ���о��Ѿ���ʼ���������ˮƽ����ת�Ƶ���������Dubois, Adolphs, 2016������һ�о������Ŀ���ǽ�������Ĵ���ͼ�ף�Joo, Boyd, et al, 2015����ϣ��ͨ��������Ի���ϸ������ȷ������֯������-��Ϊ��ϵ��Betzel, Satterthwaite,Gold, Bassett, 2017������ͨ��������Ƹ���Ч��������Եĸ�Ԥ��ʩ��Ϊ�����������ṩ��Ϣ��Petersen, 2019����
����һ���ر���о������ǻ��ƴ����������������Щ�����Ը�����˵�������Եġ�����ָ��һ������Щ�����ܹ�����һ���˵Ĵ��Ժ���һ���˵Ĵ��ԡ���������ָ����Ϊ����Ŀɿ����������нϺõ�ʱ���ȶ��ԣ���FC�����Ӽ���Byrge��Kennedy,2019�����Լ���ɼ��ص㣨Bari���ˣ�2019�������⣬ʶ�������Ѿ���ʾ���ٴ���ϵ�DZ����Svaldi���ˣ�2019�꣩������֤�������ڸ�����Ϊ����֪״̬�ķ�����Salehi, Karbasi, Barron, Scheinost, Constable, 2020, Yoo, Rosenberg,Noble, Scheinost, Constable, Chun, 2019����
����Ϊֹ�������ָ�Ʒ��������������Դ�������������ϣ����нڵ������λ�缫��Cox���ˣ�2018����������Amico��Goñi��2018��Finn��Shen��Scheinost��Rosenberg��Huang��Chun��Papademetris�� Constable��2015��������������������һ�ִ����ԵĴ�����ͨ��ģ�ͣ�����ע���������ӣ������ߣ�֮��Ļ����������ǰ���Щģʽ��Ϊ���߹������ӣ�eFC�����߹������ӹ�ע������������֮��ĶԻ�ģʽ�����Է����Ի�ģʽ����ͬ������ʱ��ı仯��ʽ��ǿ���߹������ӱ�������������ʱ���ϵĹ�ͬ�������к�ǿ�������ԣ��������߹��������������Զ����Ĺ�ͬ����ģʽ��������������Ϊ���ĵ�������������ѧѧ�����Ѿ�ȡ���˷�˶�ijɹ������ʾ������������������ص������ṹ�����Խ���������Ϊһ�������ͬ���ԵĽڵ�ļ�������Ahn, Bagrow, Lehmann, 2010, Evans, Lambiotte, 2009����������о���"��ͼ"��ʽʹ��������Ϊ���ĵķ�����Evans��Lambiotte��2009�������������������Ľ���ѧ���磨de Reus���ˣ�2014�������Ƶģ�eFCΪ�о�������֯�ṩ��һ���µĴ��ڣ������ص��������ṹ��Faskowitz���ˣ�2020�꣩�Լ�����ϵͳ�IJ����ڲ�ͬ����֮����α仯��Jo���ˣ�2020�꣩��Ȼ��������eFC�봫ͳ�Ľڵ㹦�����ӣ�nFC���ڴ��ݸ����ض���Ϣ������������Σ�Ŀǰ�Բ������
�ڴˣ�����Ӧ��һ���µ�������Ϊ���ĵĿ����̽������ʶ���е��Թ������硣Ϊ�˼���eFC������ʹ����һ����nFC���Ƶļ���������ȶԾֲ��ʱ�����н��б�����z-scoring����nFCͨ������Ƥ��ѷ���ǿ��-��������ʱ�����е�Ԫ�س˻���ʱ��ƽ��ֵ�����������ʡ����ƽ�����裬�õ�������ʱ�����С���Esfahlani, Jo, Faskowitz, Byrge, Kennedy, Sporns, Betzel, 2020,Sporns, Faskowitz, Teixera, Betzel, 2020��������ʱ�����е�Ԫ�ر�ʾ��������ڵ㣨���ߣ���֮���˲ʱ�������ķ��ȣ�����������Ļ��ͬһʱ����ͬһ����ƫתʱ��������ֵΪ����������෴����ƫתʱΪ��������ӽ�����ʱΪ�㣩��Ϊ�˼���eFC�����Ǽ���ɶԵ�����ʱ������֮�������ԣ��Ӷ��γ�һ����߾���ֱ�۵�˵�����nFC��ӳ����������֮��Ľ���������ʱ�����д����˲�ͬʱ��Ľ���ģʽ��eFC�����˲�ͬ����ģʽ֮�����������Faskowitz,Esfahlani, Jo, Sporns, Betzel, 2020, Uddin, 2020����
�ڱ��о��У����ǽ����ڹ������ӵ�ָ��ʶ����չ��������Ϊ���ĵ����硣������������������ȡ�����ݼ���Midnight Scan Club��Gordon���ˣ�2017����Human Connectome Project��Van Essen���ˣ�2013�����ֱ���MSC��HCP���Ĺ��ܳ������ݣ����DZȽ���ȫ��nFC��eFC�ڸ���ʶ���ϵı��֣�֤���������������������£�eFC��nFC���и����Ƚ���ʶ��������������Ǵ�ϵͳ�ͽڵ�ˮƽ��̽�������eFCʶ���������������أ�ʹ�û��ڽڵ����һ����עϵͳ�������������Ƿ������ģ̬����ϵͳ��صĽڵ�������Ǹ���ʶ�����Ҫ�������ء�������Dz������Ƿ��п���ͨ��ʹ��һ���������ɷ��ؽ�eFC��nFC�����ʶ�����������Ƿ������Ż�ʶ���������棬�ؽ����eFC���������ؽ����nFC��δ�����о���������eFC������������������־�����ٸ��������Ϊ�������ͼ�������ϵIJ��죬���ǵĹ���Ϊ�˵춨�˻�����
2 ���
�ڸ��о��У�����ϵͳ��������eFC��nFC�IJ���ʶ���������������������ھֲ�ˮƽ���ڵ㣩����ϵͳˮƽ���ڵ��飩�������ԺͲ��졣����һ���֣����Ƿ��������������������Ķ�����ȡ�����ݼ���the Midnight Scan Club��MSC����Gordon, Laumann, Gilmore, Newbold,Greene, Berg, Ortega, Hoyt-Drazen, Gratton, Sun, et al, 2017, Gratton, Laumann,Nielsen, Greene, Gordon, Gilmore, Nelson, Coalson, Snyder, Schlaggar, et al.�������а���10�������ߣ�ÿ��ɨ��10�Σ��Լ�����HumanConnectome Project��HCP����100���صı��ԣ�ÿ��ɨ��2�Ρ�
2.1 ʹ�����߹������Ӽ���ʶ������
����ʶ�����ʹ��"����ʶ������"��Idiff��������������ʶ��ļ��㷽ʽΪʹ�����Ӿ����ƽ�����������ƶȼ�ȥƽ����������ƶȣ�Amico��Goñi��2018b�������еĸ���ʶ��Ӧ������������nFC������ģʽ�����eFC��������������Ȼδ֪���ڱ����У����ǶԱ��˴���Ƥ��nFC��eFC��ʶ����������Կ����������������ԡ�
���ȣ����DZȽ��˴���Ƥ�㷶Χ��eFC��nFC��ʶ�������������֮������Ҫ��MSC���ݼ��е�100�ξ�Ϣ̬fMRIɨ�����ݣ�10�����ԣ�ÿ��10��ɨ�裩��������nFC��eFC����Ϊÿ������ģʽ���������Ծ�����Ϊ����nFC��eFC�����������Ԫ��֮���Ƥ��ѷ����ԣ�ͼ1e����Ȼ����������Щ�����Ծ����й��Ƴ���ͬ��ʶ��������ͼ1f����
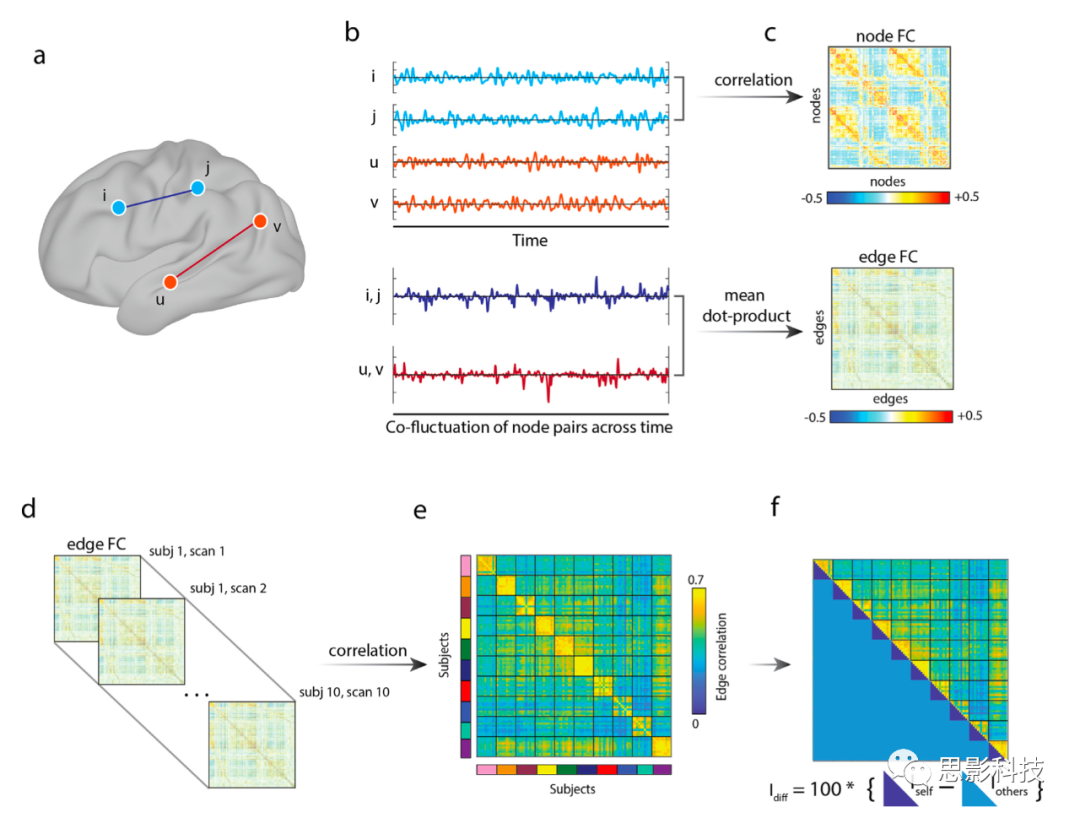
ͼ1.eFC����ʶ����������ʾ��ͼ��
��ͼ����ʹ������MSC���ݼ����������ɵġ�
(a)Ϊ��˵���ڵ������FC���ֱ�ΪnFC��eFC���ļ�����̣������ĸ��ڵ㣺i��j��u��v��nFC������Ϊ�ֲ���ijɶ�����ԡ����ڽڵ�i��j��nFCͨ����ͨ������(z-scoring)������ÿ��ʱ�����У�ִ��ʱ�����жԵĵ��������˻�ʱ�����е�ƽ��ֵ��b��c����ͬ���IJ�������Ӧ�õ��ڵ�u��v��
eFC�ļ������Ϊ�����ȼ���z-scoringʱ�����еĵ�����γ�һ���µ�ʱ�����У���Ԫ�ر�ʾ���������֮���˲ʱ�������ķ��ȣ���ʡ����ƽ�����衣
��b����ÿ��������ʱ�����м���һ�Խڵ㶨��ġ�eFC������Ϊһ�Թ�����ʱ�����е�ʱ�������ԣ�������ԡ����������Եȣ�
��c����(d)Ϊ���������ʶ��������(e)������ȡ�˱���eFC�����������Ԫ�أ���������ЩԪ�صĿռ�����ԣ��Ӷ��õ�������Լ�������Ծ�����
(f)����ʶ��������Idiff�ļ��㷽���ǽ�������ƽ�����ƶȼ�ȥ���Լ�ƽ�����ƶȡ�
���Ƿ�����ʹ��������������Ƥ��Ĺ�������ʱ��eFC�ı�������nFC�������˸����Idiff��ͼ2a������ʹ�ò�ͬ�ķ�����ͬһ���������ݼ�ʱҲ���������ƵĽ����ͼS1����Ϊ��ʹ�����ںͱ��Լ�������Կ��ӻ�������ʹ�ö�ά�߶ȷ��������Ժ����ǵ�ɨ��ͼ��Ͷ�䵽һ����ά�ռ䣬�ÿռ���±�����nFC��eFC�����Ծ����б���ijɶԾ����ϵ��ͼ2c-d������ˣ�MDSͼ������ɨ��֮��ľ��������ͨ�������Խ�ά���������ƶȡ�����ʹ�ñ�����ŷ�Ͼ���������ÿ��ɨ��ı��Ա�ǩ��k-���ڵı��Ա�ǩ��ȷ�ԡ����Ƿ���ʹ��nFC��eFC�����ƽ��ȷ��û�����Բ�����t �C test, p =0.9786�������Ա�ǩ��ȷ�Ա�����ΪMDS�ռ��оŸ�����ĵ�����ɨ��ı��Ա�ǩ��ƥ��ı��Եİٷֱȡ�
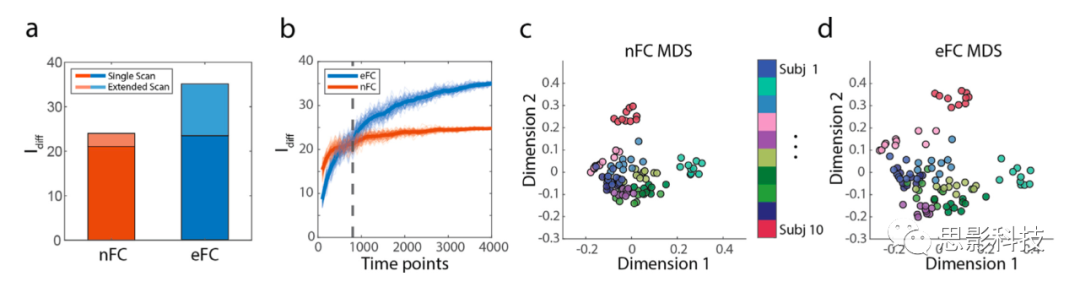
ͼ2.eFC��nFC�ĸ���ʶ���ɨ�賤�ȵ�Ӱ�졣
��ͼʹ������MSC���ݼ����������ɣ�������200���ڵ��Schaefer������
(a)����ɨ��ģ���ɫ�������̶ȵ�����ɨ�裨dzɫ��nFC��eFC��Idiff��
(b)��ɨ�賤�ȼ����eFC��nFC��Idiff����ɫ���ߣ�800��ʱ��㣩��ʾeFC��������nFC��ʱ�����еij��ȡ���ɫ�ͳ�ɫ�Ĵ�����100�ε�����ƽ��Idiff��ϸ�߱�ʾ��ɨ�賤��ÿ�ε�����Idiff��
(c)ʹ�ö�ά�߶ȷ��������˱��Ե�nFCɨ��ͼ��
(d)ʹ�ö�ά�߶ȷ��������˱��Ե�eFCɨ��ͼ��ÿ�����Ե�ɨ�����ֱ��Ӧ��c-d֮��ɫ���ϵ�һ����ɫ��
��ǰ��ķ����У�����ʹ�ô�Լ30���ӵ����ݣ�MSC���ݼ��е�session�ij���ʱ�䣩����eFC��nFC��������������˸���ʶ�������Ƿ���ɨ�賤�ȵĵ��ڣ���Idiff�Ƿ����ſ����������仯��Amico, Goñi, 2018, Bari, Amico, Vike, Talavage, Goñi, 2019����Ϊ�˲�����һ�㣬���������˸��̻������session�������е�ɨ���Ϊ������������Ƭ�Σ����߽����ɨ������������������γɸ�����session��������100���������������ı��˹�ɨ��session��ʱ�䣬��100��ʼ��4000����������ȡ�������ظ���100�Ρ����Ƿ��֣�������500��ʱ��㣨Լ20���ӣ�ʱ��nFC��Idiff��eFC����p < 10-6��t - test����ͼ2a��Ȼ��,��800��ʱ��㣨Լ30���ӣ���ʼ��eFC��������nFC��p < 10-4;t - test����ͼ2b������ʹ�ò�ͬ�ķ��������ݼ����������ƵĽ����ͼS1��������ʹ��eFC�Ľ������ǰ���о���һ�µģ���ʹ�ô�ͳ��nFC��ʶ����������ɨ�賤�ȵ����Ӷ�������Amico, Goñi, 2018, Bari, Amico, Vike, Talavage, Goñi, 2019�����ܵ���˵�����ǵ��о��������ֻҪ���㹻������������Լ30���ӣ�����ʹ�ڲ�ͬ��session��eFC��nFC���Ƚ���ʶ��ͬ������
2.2 ����Ƥ��eFCʶ�������ľֲ���������
����һ���У����Ƿ��������㹻����������������£�eFC��nFC�������������Ƥ���ʶ�������������������ҳ�����һ�Ľ��������Ĵ�����������ʹ���˽ڵ���һ��������ÿ����������Ը���ʶ�����������Ӱ����Ȼ��Ϊ�˶Խ�������ܽᣬ���Ǹ��ݵ��͵Ĵ���ϵͳ�Խڵ���з��飬����ͳ��ѧ�Ƕ�����ÿ��ϵͳ������ʶ�������Ĺ�����eFC�����ɶԵ�����֮�������ã�ÿ�����߶���Ӧһ�Դ�������Ϊ��ȷ����Щ������������ЩЧӦ�����ǵ�����ɾ����200�������е�ÿһ����������ʹ��ʣ���199���������¼���eFC��Idiff��Ȼ�����ǽ����Idiffֵ��ʹ���������ԣ�����200������õ�ֵ���бȽϡ���������Ǹ��ݹ���ͼ�ף�Schaefer���ˣ�2017�꣩����ġ����ǻ������ߴ���ڵ���������Ƶķ�����������ͼS2�����Ƿ��ֵ�ɾ��λ�ڿ��ƺ����������Ƥ���������˲���ʶ�������Ľ��ͣ���ɾ���������˶�����Ե���Ӿ��������������������ʶ��������ͼ3a��Ϊ�˿��ӻ������ǽ���Idiff�ķ��ŷ�ת��������ϵͳ�����нڵ���з��飬���ӻ�ÿ���ڵ�Ը���ʶ�������Ĺ��ף�ͼ3b����ÿ���ڵ�Ĺ��ױ�����Ϊû��һ���ض��Ľڵ��Idiff��ȥ����200���ڵ��Idiffֵ�����磬��ͼ3b�У��ڹ���eFC֮ǰ���ӿ���Aϵͳ��ɾ��һ���ڵ㣨��һ���Ƶ��ʾ����������Idiff���٣�������Ϊ���Idiff������Ӱ�졣���֮�£��ӱ�Եϵͳ���Ƴ�һ���ڵ�ᵼ��Idiff���ӣ����������Ϊ���Idiff�и���Ӱ�졣
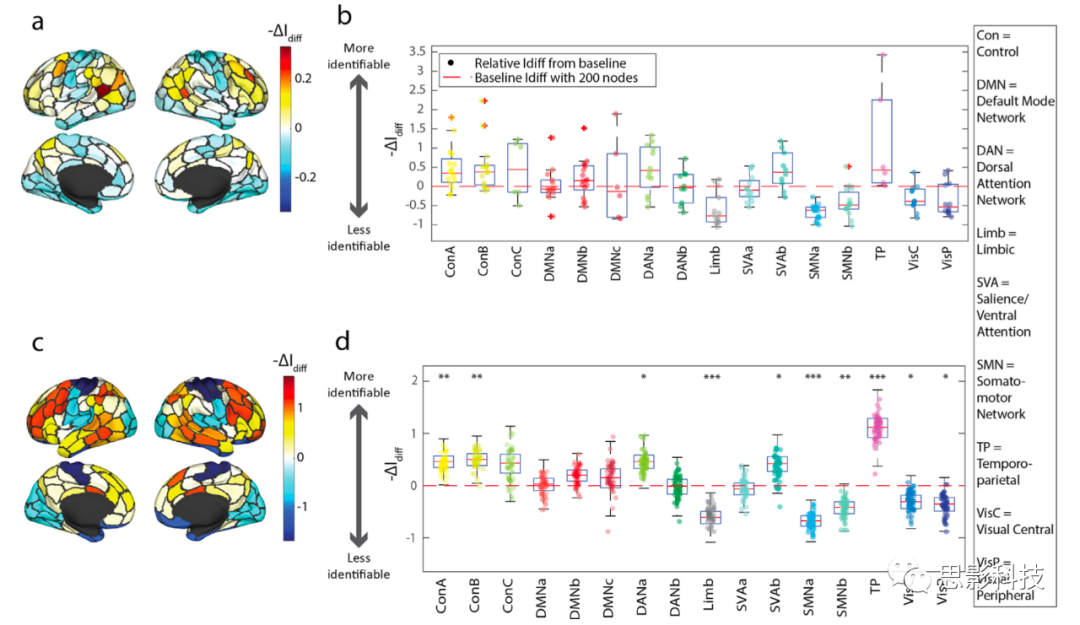
ͼ3.�ڵ��eFC��ʶ�������Ĺ��ס�
(a)Ϊ������������Idiff�Ĺ��������Ǽ�����ȥ��ÿ���ڵ㣨N=200���ϵ��������ߺ�Idiff�ı仯��������ʾ��Ͷ�䵽Ƥ������Idiff�仯��
(b)���Ǹ��ݴ���ϵͳ�������ڼ���eFC֮ǰɾ��ÿ���ڵ��Idiff�����Ӱ����
(c)�ڹ���eFC֮ǰ�ų�����ϵͳ�Ľڵ㣬��ʾ���ض�ϵͳ��Idiff���������Ӱ�죬����(d)�����ȥ��ƥ�������Ľڵ���ȣ���Idiff�����Բ�ͬ�Ľ��(BonferroniУ����pֵ��* = p < 0.003, ** =p < 0.0006, *** = p < 0.00006)��Ϊ��ֱ�۵�չʾ��������ǽ���Idiff����Ϊ-��Idiff����������һ���ڵ���Ƴ�������Idiff�����Ӱ�졣���һ���ڵ���Ƴ�����Idiff�Ľ��ͣ�����ڵ��ʶ�������Ĺ�������Ϊ��"����Idiff"��
�����������������������ɾ��ƥ�������Ľڵ���ȣ��ĸ�ϵͳ�Ľڵ��ʶ������������Ӱ����ͼ3c-d����ͨ���������ϵͳ��ǩ��10,000�ε��������ڵ㱻��������·����ϵͳ�����Ƿ��֣����ӿ���A������B������ע��A��ͻ�Ը�������B��������ɾ���ڵ�ʱ��ʶ�����������ɾ��ƥ�������Ľڵ�ʱ���Խ��ͣ���ˣ�ͼ3d����Щϵͳ��Ӱ��Ϊ����ģ������⣬���Ƿ��������ɾ��ƥ�������Ľڵ���ȣ�ɾ����Ե�������˶�A��B������ͱ�Ե�Ӿ�����Ľڵ���������ʶ����������ˣ���Щ�����Idiff��Ը����ЧӦ������ͼ3d�У���
���������������ýڵ���һ������ʾȫ��ʶ�������������������ء����Ƿ��ְ�����Ҷ����ϻ����������ʶ���������������˶�����Ե���Ӿ���������ʶ�������Ľ��͡���Щ����ϵͳˮƽʶ�������Ľ���ںܴ�̶�����֮ǰʹ�ô�ͳ�ġ��Խڵ�Ϊ���ĵĹ������ӵ��о�һ�£�Finn, Shen, Scheinost, Rosenberg, Huang, Chun, Papademetris,Constable, 2015, Mueller, Wang, Fox, Yeo, Sepulcre, Sabuncu, Shafee, Lu, Liu,2013, Peña-G��mez, Avena-Koenigsberger, Sepulcre,Sporns, 2018����������������֯�����ʶ�λ��һ���ض���ϵͳ�Ӽ���
2.3eFC��ϵͳ�ͼ�Ⱥ��ʶ������
��ǰ��IJ��֣�����֤������һ���㹻����fMRIɨ���У�eFC�ĸ���ʶ������nFC�������뵥ģ̬��ȣ���ģ̬�������������ʶ����������������Ǽ����о���������Ƥ��ʶ���������������أ��ص��ע��eFC��ÿ�����Թ���ϵͳ��ʶ�������Ĺ��ס��ڱ����У�����ּ�ڻش���Щ���⣺���Ե�һϵͳ�����߶�ʶ�������кι��ף���Ⱥ���ߵ�ʶ������������Σ�
Ϊ�˽���������⣬��������ֻʹ�����ض�����ϵͳ��ص����Ӷ�Idiff���й���������nFC������ζ��ֻʹ��������ڵ㣨����һ�����ߵ����������������䵽ͬһ����ϵͳ������������ʶ��������Schaefer���ˣ�2017��������ʹ��eFC���߶Խ��������ƵIJ�������Ҫ���빹��eFC��Ŀ������������ص������ĸ��ڵ㱻���䵽ͬһϵͳ��һ����˵�����Ƿ���eFC��nFC��ϵͳ�����Idiff�Ǹ߶���ص���R = 0.9578, p < 10-8��ͼ4b�������DZ����˰�Idiff�����ǰ����ͺ����ϵͳ�����Ƿ������ڵ㶼��Դ��������A������B��Ĭ��ģʽB�ͱ���ע��B����ʱ��Idiff����������ͼ4a�����෴�����Ƿ��֣����ڵ����������˶�B��ͻ�Ը���ע��A������C����Ե�Ӿ��ͱ�Ե����ʱ��Idiff�����Ƚ�С��ͼ4a��������ע���Щ��ϵͳ�����߶ԣ�����õ�ϵͳָ�������������漰�����ĸ��ڵ㶼����һ��ϵͳ��ֻ����eFC�����һС���֣�<1%������ˣ���Щ���ֻ���ھ���Ԫ�ص��Ӽ�������eFC�����˸��㷺�����߶ԣ�����һЩ�漰Դ�Զ���ĸ���ͬϵͳ�Ľڵ㣬���ǽ�һ��������eFC�ڼ�Ⱥ����������
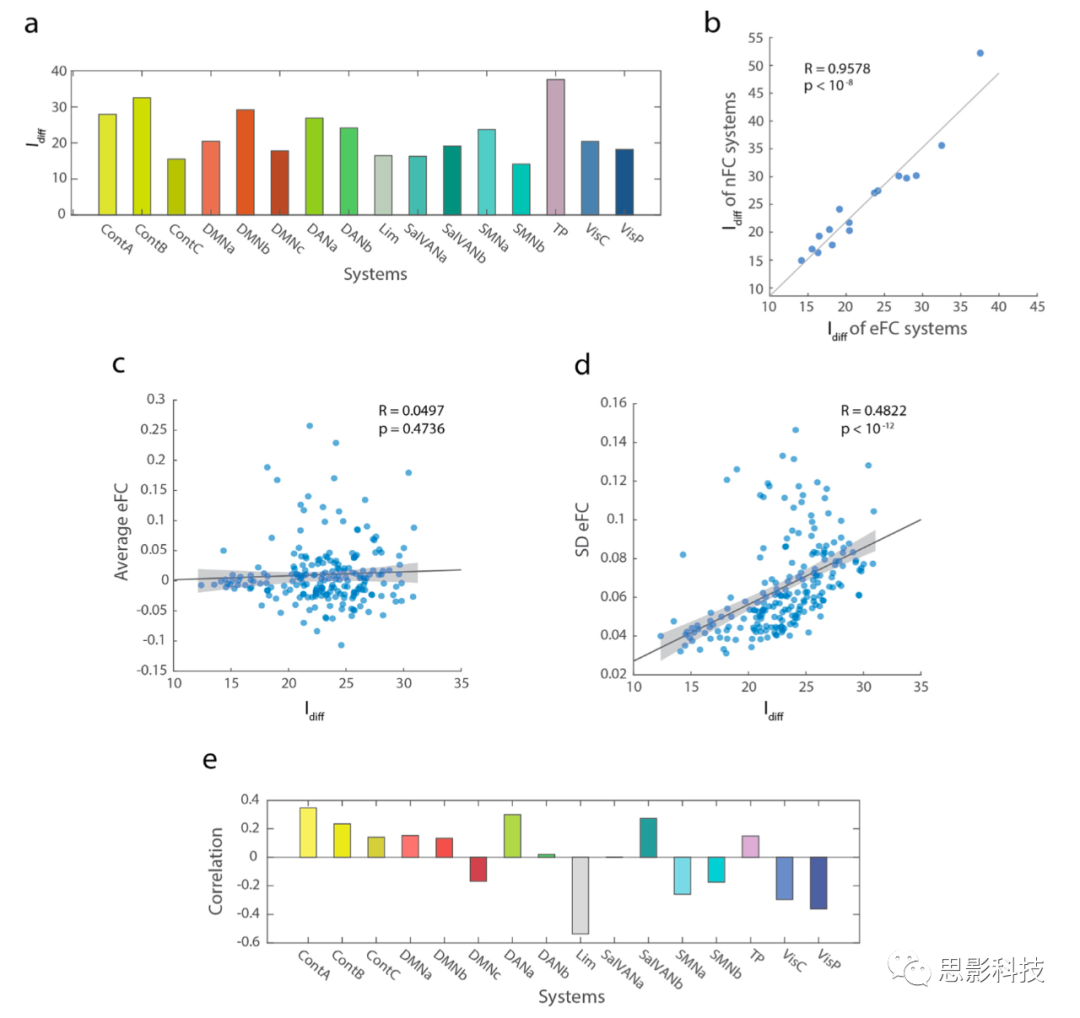
ͼ4.���߹������ӣ�eFC����ϵͳ�ͼ�Ⱥˮƽ����������MSC���ݼ��У�eFC�ı����ںͱ��Լ���������ʾ�˲�ͬϵͳʶ�������IJ��죬����ʹ��FCϵͳ��ʶ�������߶���ء�
��a����ʾ��10�����Ե�10��rsfMRIɨ���ϵͳeFC�ı����ڼ�ȥ���Լ�������ԡ�
��b��ϵͳeFC��nFC��ʶ������֮��ĸ߶�����ԡ�
(c) Idiff��ÿ����Ⱥ��eFCƽ��ֵ����أ���(d)ÿ����Ⱥ��eFCֵ�ı�����Idiff������ء���ɫ��Ӱ��ʾ��95%���������䡣
(e)16�����͵Ĵ���ϵͳIdiff��eFC��Ⱥ������ԡ����еķ�������ʹ��MSC 200�ڵ���������еġ�
Ϊ�˵���ڵ����Բ�ͬϵͳ��Ⱥ�����߶Ե�Idiff������ʹ�ñ���k-means�㷨������ŷ�Ͼ����eFC��������˾��࣬�����������k=2��20��Ϊ�ˣ��������ȶ���ƽ��eFC��������ɨ��ͱ��Ե�ƽ��ֵ��ͼS4a-b�������������ֽ⡣���DZ���ǰ50���ɷ֣�Ȼ������Ϊk-means�����㷨�����루ͼS4c��������һ�������ľ���k�������ظ���250���㷨��ͼS4d��������250�ι����У����DZ�����һ���������ԣ���ƽ���������������������ƣ��ķ�����ͼS4e�����������Ľ���ǽ�ÿһ��k��������Ϊ���ص�����������Ҫע��������������ʹ����ƽ��eFC������еģ���������类�Եļ�Ⱥ��ƥ�䡣
Ȼ��������eFC�����������ʶ��������ϵ������������˵������ʹ���������Ⱥ������-�������ӻ���Ϊ"����"��������ָ���Ǽ�Ⱥ�ںͼ�Ⱥ������߶ԣ���Щ����λ�ڳɶԵ�����֮�䣨ͼS4f����Ȼ����ÿ�����飬����ͨ������ЩȨ�ر���Ϊ��������������ɨ������Щ���ӵ�ƽ��ֵ�ͷ������������������ЩȨ�ؼ�������и����ɨ���֮������ƶȣ�������Щ���ƶ�ֵ�м�����������ʶ����������Щ����õ���ÿ�����������ָ�꣺
1��ÿ��ɨ����������-�������ӵ�ƽ��Ȩ�أ�
2��ÿ��ɨ����������-�������ӵı�ƫ�
3��ʹ������ɨ�������-����������Ƥ��ѷ��صľ����ʶ�����������ÿ��k���࣬���Ǽ���������ֵ�ڸþ����������������ϵ�ƽ��ֵ��Ȼ��������ͼ4c-d�л�����ʶ��������ƽ��ֵ�ͱ�ƫ��ֵ�Ĺ�ϵ������ÿ��k�����Ǽ�����"����"��Idiff��ͼ4����
�漰ÿ����Ⱥ�����������Idiff��ƽ��ֵ�ͱ������Ϊÿ����Ⱥ�Ĵ���ֵ��������̲�����ͼ4c-d�е�209���㣨k = 2-20����������˵�����Ƿ���һ����Ⱥ��ƽ��eFC������Idiff��R = 0.0497��p = 0.4736��ͼ4c������ء����⣬��ijһ������ص�eFCȨ�ص�ƽ���仯����Idiff��R = 0.4822��p < 10-12��ͼ4d��������ء���Щ����ָ���ǵ�eFC����Ⱥ��ǩ��������ʱ����Ⱥ�ڵ�����-����Ȩ�أ�ͼS4f����
ÿ�����鶼��Ӧ�ڷ������ͬ���������֮���һ������-�������ӣ�eFC��������ÿ�����飬��������������-�������ӵ�ƽ�����ͱ�����������˷ֲ����������ƺͱ仯�ԡ����Ƿ�������-�������ӵ�ƽ��Ȩ����ʶ������û��������ϵ��Ȼ����һ�������ڵ�����-�������ӵı�������ϸߵĸ���ʶ������������ء����ǻ�������nFC��k = 2-20���ľ�����������Idiff�Ĺ�ϵ��ͼS5������ʹ��eFC�ó��Ľ����ͬ��ƽ��ֵ��R = 0.0497��p = 0.4736�����R = 0.4822��p < 10-12�������Ƿ�����nFCʱֻ�н��������ģʽ��ƽ��ֵ��R = 0.1392��p = 0.0444�����R = 0.1494��p =0.0309����
��Щϵͳ���ܵ����˸�ˮƽ��Idiff ��Ϊ�˽��������⣬���Ǽ�����ÿ��ϵͳ��һ�������ļ�Ⱥ�б�������Ƶ�ʣ���Ϊÿ������ϵͳ�ֱ���������Ƶ����Idiff������ԡ����Ƿ��֣���Ⱥ�е����ơ�Ĭ��ģʽA��B������ע�⡢ͻ�Ը���ע�������ڵ��뼯Ⱥ��Idiff������ء���Ⱥ�еı�Ե��Ĭ��ģʽC�о��˶�ϵͳ�������˶����Ӿ�����Idiff�ļ����йأ�ͼ4e����
��֮����Щ�����������eFC�У��߽���֪ϵͳ������ơ�ע���Ĭ��ģʽ���磬��������߸���ʶ�����������о��˶��ͱ�Ե����ή����ʶ��������������һ����������Щ�����֮ǰʹ��nFC�ķ�����һ�£���֤�����Ƶ�ϵͳ�������ٽ��˸���ʶ����������ǿ��Finn,Shen, Scheinost, Rosenberg, Huang, Chun, Papademetris, Constable, 2015,Mueller, Wang, Fox, Yeo, Sepulcre, Sabuncu, Shafee, Lu, Liu, 2013�������⣬���ǵĽ������������Ȩ�ص����������ԺͿɱ��Կ����ǽ���ΪʲôijЩϵͳ��ϸ�ϵ͵ĸ���ʶ��������ص�һ������ԭ��
2.4 ʹ��PCA�ع���eFC����˸���ʶ������
���о�����������ʹ��������eFC�����������-�������ӵ��ض��Ӽ�����Idiff�ļ��㡣��Ϊ���ķ���������������Ƿ����ͨ��ʹ����Խ��ٵ����ɷ��Ż��ؽ�eFC����߲���ʶ��������
��ǰ���о�ʹ����nFC�����ɷַ�����PCA�������ʶ��������Amico, Goñi, 2018, Bari, Amico, Vike, Talavage, Goñi, 2019���������֮���ó�����Ҫ�����б��Ժ�ɨ���nFC���ڱ�����eFC��������һ����Ԫ��ɨ��ĵ�һ�����þ���ֽ�Ϊ�����ɷ֣�PC������ͨ������Խ��Խ���PC����������ֵ�Ľ������ؽ�eFC����ÿ�ξ����ؽ�֮ǰ���ؽ�֮�����Ƕ������ÿ������PC��ÿ��ɨ���eFC��Idiff���ڴˣ����ǽ���һ����Ӧ����MSC���ݼ��е�nFC��eFC��
ʹ�������ؽ����������Ƿ���nFC��eFC��Idiff�����Ա��Ż�����nFC��eFC�У�Idiff��k=10�ijɷ��ϴﵽ�˷�ֵ����Ӧ�ڱ�����������eFC��ʶ������������nFC����Idiff = 21.17��ȣ���ֵΪIdiff = 35.27��ͼ5b��e�����ز�Ƚ���Ҳ��������Щ�����ͼS8������ô��Ϊʲô�ڶ�ʶ�����������Ż�ʱ��PC���������뱻�Ե�������ƥ�䣿�������Ȳ�����ÿ�����Ե�ɨ����������ʶ��������PC������Ӱ�졣����100�������в���ÿ�����Ե�����ɨ�裨ͼS7c���ʹ�10�����������ѡ�������ɨ�裨ͼS7a��ʱ���Ż�ʶ�����������PC���������ݼ�������������������Ƕ�����HCP���ݼ���N = 100��ÿ����������ɨ�裻ͼS7e���ͽ�HCP���ݼ���ɨ�賤�ȣ�2400��ʱ��㣩��MSC���ݼ���800��ʱ��㣻ͼS7f����ƥ��ʱ����Щ����������֡�
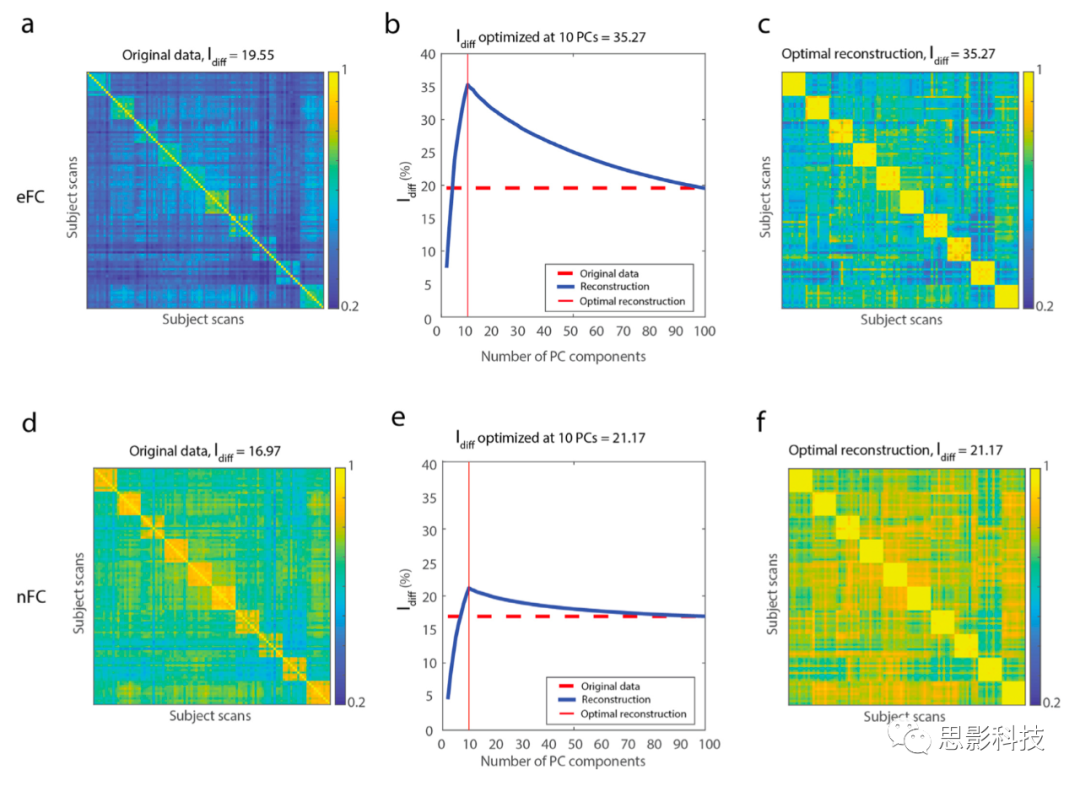
ͼ5.ʹ��eFC��nFC���в���ʶ�������Ż���PCA�ؽ���
(a)��PCA��ԭʼ���ݣ�֮ǰeFC��ɨ��������ԣ�Ƥ��ѷ��أ�����
(b)��PC= 10ʱ�����Idiffֵ����ɫ������Idiff��ԭʼֵ��
(c)Ϊ������Idiff��ʹ��10��PC�ؽ�eFC�������
(d)PCA֮ǰ(ԭʼ����)nFC��ɨ���������(Pearson�����)����
(e)��PC= 10ʱ�����Idiffֵ����ɫ������Idiff��ԭʼֵ��
(f)Ϊ������Idiff��ʹ��10��PC�ؽ�nFC�������
�������̽���˿�����ߣ�PC = 1-10���ͣ�PC = 11-100��ʶ��������PCϵ������һ���ɷ֣�PC1��������ѧ�ǶȽ�����eFCֵ��ɨ��Ϳ类�Ե������졣PC1��Ψһһ��ϵ��ͳһΪ���ijɷ֣�ͼS9�����������ľŸ�ϵ����PC = 2-10�����ֳ��˶�Ӧ�ڵ������Ե��ſ�����ģʽ��ͼS9����������ģʽ��PC = 11-100��ͼS10��ͼS11��ͼS12����û�г��֡�
��֮ǰ�ı���һ�£�Amico, Goñi, 2018, Rajapandian, Amico, Abbas, Ventresca, Goñi, 2020�������ǵĽ��������ͨ����ѡ��ر��������ݼ��еı���������ƥ��ijɷ��Ӽ���������߸���ʶ�����������Ƿ�����nFC��ȣ�ʹ��eFC�ĸĽ�����Ҫ��ö࣬�������nFC��ȣ�eFC���Ը��õز����Ի���������������Svaldi, Goñi, Abbas, Amico, Clark, Muralidharan, Dzemidzic, West,Risacher, Saykin, et al., Svaldi, Goñi, Sanjay, Amico, Risacher, West,Dzemidzic, Saykin, Apostolova, 2018����
�������Թ���������ģ̬��Ӱ�����ݴ�������Ȥ�������˼Ӱ�������ӣ�ֱ�ӵ���������������лת��֧�֡�(�������ź�siyingyxf��18983979082��ѯ)��
�Ϻ���
����ʮһ��Ź������������ݴ����ࣨ�Ϻ���10.28-11.2��
����ʮ�Ž�Ź�����Ӱ������ࣨ�Ϻ���11.4-9��
��ʮ�Ľ�����̬���ܴŹ������ݴ����ࣨ�Ϻ���11.30-12.5��
���죺
����ʮ��Ź�����Ӱ������ࣨ���죬10.22-27��
�ڶ�ʮ�˽���ɢ�������ݴ����ࣨ���죬11.5-10��
��������ɢ�Ź��������߰ࣨ���죬11.17-22��
�ڶ�ʮ����Ź�����Ӱ��ṹ�ࣨ���죬11.27-12.2��
�Ͼ���
����ʮ����Ź������������ݴ����ࣨ�Ͼ���10.16-21��
�ڶ�ʮ����Ź�����Ӱ��ṹ�ࣨ�Ͼ���10.24-29��
����ʮһ��Ź�����Ӱ������ࣨ�Ͼ���11.12-17��
�ڶ�ʮ�Ž���ɢ�������ݴ����ࣨ�Ͼ���11.19-24��
������
��ʮ�����������ݴ�����߰ࣨ������10.20-25��
��ʮһ��Ź���ASL������������ǣ����ݴ����ࣨ������11.3-6��
����ʮ����Ź�����Ӱ������ࣨ������11.9-14��
������Ӱ����ѧ�ࣨ������11.25-30��
�����R����ͳ�ưࣨ������11.16-20��
���ݴ���ҵ����ܣ�
˼Ӱ�Ƽ����ܴŹ���(fMRI)���ݴ���ҵ��
˼Ӱ�Ƽ���ɢ��Ȩ����DWI/dMRI�����ݴ���
˼Ӱ�Ƽ��Խṹ�Ź����������ݴ���ҵ����T1)
˼Ӱ�Ƽ����������У�QSM)���ݴ���ҵ��
˼Ӱ�Ƽ������ද���С����Ӱ�����ݴ���ҵ��
˼Ӱ�Ƽ��鳤�ද��fMRI����ҵ��
˼Ӱ���ݴ���ҵ������ASL���ݴ���
˼Ӱ�Ƽ���Ӱ�����ѧϰ���ݴ���ҵ�����
˼Ӱ�Ƽ������Ⱥ����ҵ��
��Ƹ����Ʒ��
˼Ӱ�Ƽ���Ƹ���ݴ�������ʦ ���Ϻ����������Ͼ���
BIOSEMI�Ե�ϵͳ����
Ŀ��ʽ���ܴŹ���̼�ϵͳ����
3 ����
3.1 ���߹���������ǿ�˸���ʶ������
���ĵĺ����ǹ۲쵽����ڴ�ͳ�Ļ��ڽڵ������nFC��eFC����߸���ʶ��������nFC������������֮����������-һ����أ�Owen���ˣ�2019����eFC�������߶�֮�乲ͬ������������-�߽������Faskowitz���ˣ�2020�����˽�����ĸ߽���֯��������ѧ���б�֤�������ã�Ahn, Bagrow, Lehmann, 2010, Evans, Lambiotte, 2009, Nepusz, Vicsek,2012, Trinh, Kwon, 2016�������Ĵ�������Ϊ���ĵ��ӽǣ�ʹ�����ܹ����߽Ĵ���������֯��ѧ�Ƶľ���������ϵ������
eFC��Ϊһ���߽��ؽ��Ƿ�ᵼ�¸���ʶ�����ߡ������������Ҫ�о�ȫ��nFC��eFC��ʶ�����������ڸ�����������ݣ�eFC�Ƿ��������Ǹ�ȷ��ʶ��һ���������壿���ǻ�����ʹ��eFC��ʶ���Ƿ���ܵ�ɨ�賤�Ⱥ���������Ӱ�졣�ܵ���˵�����Ƿ���������㹻������������Լ800��ʱ����30���ӣ���eFC��ʶ��������������nFC�����⣬����ע�ʹ��eFC�����Idiff��ʹ�ô���ɨ�������»�ﵽ�����Idiff����һ������ܷ�ӳ��eFC�ĸ߽�������ʵ���ϣ�eFC������������Ե�����ԣ���nFC��Ҫ��������������һ���ȶ��Ĺ��ƣ�Bourin��Bondon��1998�������ǵĽ������������һ���Ƶ��ȶ���eFC���ܱ�nFC�ڱ�����Ի��������������������ơ�
������������ʶ��������Amico��Goñi��2018b����һ��������ɨ���������뱻�Լ�ɨ����������ȵ��ܽ���ָ�꣬���Ƕ�������˲�������Ȼ������������ָ����Ƥ��ѷ��أ�Finn���ˣ�2015����I2C2��Shou���ˣ�2013���Ѿ��Ƚ���ʶ���˱��ԣ�IdiffҲ���ǵ��˱��Լ�ɨ�������ԣ�Bridgeford���ˣ�2020������ˣ�һ���߶ȿ�ʶ���ɨ�費���������Ƶģ����һ����������Ե�ɨ�費ͬ������ע���������μ���Idiff������ڱ���������ÿ�����Ե�ɨ��������ܻ��Idiff���ƫ���ʹ�ò�ͬ���ݼ���Idiff���Խ���ֱ�ӱȽϺͽ��͡����ǻ����ֿ�I2C2��Discriminability�Լ�Idiff��MSC 100��HCP 100�ڵ����ݼ��Ļ�������Idiff��ʾ����ߵĸ���ʶ��ˮƽ��ͼS13����
���ǵĽ�����������ݼ���������ͬ�ķ����еõ������֡���Щ��������߽�����ṹ��������Ҫ�ĸ����ض���Ϣ����ˣ�������Ϊ���ĵķ������Ը��õIJ��������������������Щ�۲�������սҲ��չ�˵�ǰ���ڸ���ʶ��;�ȷ����ӳ���֪ʶ�����ǵĽ����һ����������ȱ��͵�̽��������Ҫ�������Ը�������ݡ�δ����Ҫ�����˽�ɨ�賤�ȣ����������߽״��Ա���֮��Ĺ�ϵ����eFC��Owen���ˣ�2019����
3.2 ��ģ̬������������ʶ��
��Щ��������������eFC�ĸ��������ԣ��Ƿ����ض��Ĵ�������ʹ���Ը�������ѱ�ʶ��Ϊ�˻ش���Щ���⣬������������ͬ�ij߶��Ϸ����˸���ʶ�����������ȣ������ýڵ���һ��������ÿ���ڵ��Idiff�Ĺ��ס����Ƿ��֣����ڹ���eFC����֮ǰɾ��ijЩ�ڵ�ʱ���ᵼ��Idiff���Լ��ٻ����ӡ��ر������Ը߽�ϵͳ�Ľڵ�����ߵ���Idiff���Եļ��٣�����Щ��о��˶��ͱ�Ե������صĽڵ�������ڹ���eFCǰ���Ƴ�ʱ�����˸��ߵ�ʶ����������Щ����֧�������ڵ�nFC���������ڵ�ģ̬�ͳ����й��������߽ס���ģ̬���ܵ�������������Ҷ����Ҷ���Ҷ���������˸���ʶ����Finn���ˣ�2015����
Ϊʲô��ģ̬�������������ڼ�ǿʶ��������һ�����ܵĽ����������ǵĶ�����йء����ƺ��Ҷ�����е�������Ϊ֧�ָ�����֪���������̣�����Щ�����Ǿ��и������ġ���Щ����Ĺ�������ģʽ�����ڲ�ͬ�ı���֮���кܴ�IJ��죨Mueller���ˣ�2013�꣩���Ǵ���Ƥ���ڽ���������������չ�IJ��֣�Sepulcre���ˣ�2010�꣩������������������չ�IJ��֣���˿�����������������γɵģ�Elston���ˣ�2009�꣩�������������۲쵽��ģ̬�����������˵Ĺ���ָ����������������֪�������ͽ������̵��ۺ�Ӱ�졣Ȼ������Щ���̵�ȷ�л��ƻ��������Ӧ����δ�������Ŀ�ꡣ
Ȼ������̽���˽ϸߺͽϵ͵�Idiff�Ƿ������Ե�һ���ʹ���ϵͳ�����߶Ե��µģ�Schaefer���ˣ�2017����Ϊ�˽��������⣬���Ǵ�ֻʹ��16������ϵͳ�е�һ������ϵͳ���������߶��У��ֱ�����˱��Ե�eFC�������Ƿ��֣����Ե�ϵͳ��eFC��nFC��ʶ����������������صģ����ҴӶ�ģ̬�����γɴ���������������нϸߵ�Idiff�����仰˵����һϵͳ�ڵ��ھ����߶Բ����ܵ���ȫ�Է�Χ��eFC����ߡ��෴�����������ڲ�ͬ������֮������߿���������eFC��Idiff����nFC��ԭ����
���Խڵ���һ���͵�һϵͳIdiff�Ľ���������ض��Ĵ���������Щ����߽״��Թ��ܵ����������Ÿ���ʶ���ڹ��������о��з�����Щ�߽���������ʾ����ߵı��Լ���죨Miranda-Dominguez,Mills, Carpenter, Grant, Kroenke, Nigg, Fair, 2014, Mueller, Wang, Fox, Yeo,Sepulcre, Sabuncu, Shafee, Lu, Liu, 2013��������������Ĺ��������ѱ������ڽ����������µģ�Zilles���ˣ�1988�����漰������Choi,Shamosh, Cho, DeYoung, Lee, Lee, Kim, Cho, Kim, Gray, et al., 2008, Cole,Yarkoni, Repovš, Anticevic, Braver, 2012����һ���ܵ����ţ��ᵼ�������ϰ���Fornito, Harrison, 2012, Greicius, 2008�������⣬�ݱ�����ʹ��nFC�Ը���ĸ߽������Ľ���ʶ�𣬿���Ԥ������������Amico, Goñi, 2018,Finn, Shen, Scheinost, Rosenberg, Huang, Chun, Papademetris, Constable, 2015�����ۺ����������ǵĽ����ʾ������ʶ�������߽��ܶ�Դ�ڶ�ģ̬���������������ԵĹ��ܿ������Դ����Թ��ܡ�
eFC��nFC�����еĶ��������������˼�����������Ϊ��ƥ�����ǵ�ά��ȷ������ƽ�ıȽϣ����ǽ�nFC��eFC�������Ϊ��ͬ���������������Ƿ��֣�����-�������ӵķ��������ʶ�������أ�����Щ���ӵ�ƽ��Ȩ����û�С�Ȼ�������Ƿ���ʹ����ƽ����nFC����õ��Ĺ�ϵ��Խ�������ˣ����ǵĽ����һ��������eFC������-�������ӵIJ������Ǹ���ʶ��������һ����Ҫ���������ǻ����֣������뵥ģ̬����ϵͳ��������ɵļ�Ⱥ��ȣ�������Դ�ڶ�ģ̬ϵͳ���ߵļ�Ⱥ��ʶ������ˮƽ���ߡ���Щ�����nFC�о��Ľ����Finn, Shen, Scheinost, Rosenberg,Huang, Chun, Papademetris, Constable, 2015, Peña-G��mez,Avena-Koenigsberger, Sepulcre, Sporns, 2018���Լ�����漰eFC��Ⱥ���о���Jo���ˣ�2020��һ�¡����ǵ��о����������ϵͳ�ͼ�Ⱥ������Ȩ�صı仯����������������ָ�ƺ�ʶ��������һ����Ҫ������
�����ǵķ����У�����ʹ��������100��200���ڵ��Schaefer������Schaefer���ˣ�2017����Yeo17���������磨Thomas Yeo���ˣ�2011������ȻSchaeferͼ���ṩ��һ����100��1000���ڵ�ĵ�������չ�ķ����������ڼ����ϵ����ƣ�û�ж�Schaefer���и�ϸ�ķ����Խ��в���ʶ�������ͺ�������������ͼS1�Ľ������MSC��HCP���ݼ��У�eFC��nFC��100��200�ڵ�����и�����ʶ��Ȼ�������Žڵ�����100�����ӵ�200����ʶ�������ľ��Բ�������ˡ���Ҫ��һ���ķ��������Ը�ϸ�ķ����еĸ���ʶ�������������տ��ܵ���eFC��nFC��Idiff�ﵽһ����ֵ����������ģʽ�Ĵ��Թ�����������Ķ�ģʽ�������ܱ������������ĸ���ʶ����������Ҫ��һ�����о���ȷ���ڲ���ʶ����������ķ�����Ԫ��������Ӱ�졣
�ܵ���˵�����ǵ��о������������ʶ���������Ը߽״���ϵͳ�Ķ�ģ̬���������ġ���Щ�۲��������ɾ��б����ض���Ϣ���Ƚ������������־�������Ե�Ӱ�죬ͬʱ����������������ٵ����Ӽ�������Ҫ���ǣ����ǵ��о�������������и߷����eFC��Ⱥ��Ҳ������ˮƽ�ķ����б�����������������ȷ�����Ե��ض���Ϣ����Ի�ҽ�ơ����⣬�����о�Ϊδ����������������־���ṩ�����������о������ڽ�һ����ȷ��fMRI�ɼ������������ʶ��������Ӱ�죬�����ڲ�Ҫ��ɨ�賤�ȵ����������ȵ���߱��Ե������ԣ��ر��Ƕ��ڴ������ٴ���Ⱥ��Laumann���ˣ�2015�꣩�����eFC����ľ����ڲ�ͬ�ı����еĽ�����Ƚ��ģ���ʾ����Ϊһ�ֽ�ά������DZ����δ���Ĺ����б�Ҫ��ȷ����ˮƽ����ˮƽ�����������³���Եļ�Ⱥ�������Ӽ��������ͱ��Լ������Ժʹ��Ե�eFC�Ƿ�������״̬�ĵ��ڡ�
3.3 ���ɷַ���ͻ����eFC��������
�����������ѭ���µ�nFC�о�����PCAӦ����eFC���ݣ���Ч�ؽ�eFC��ԭΪһ��С�����ɷ���Amico, Goñi, 2018, Bari, Amico, Vike,Talavage, Goñi, 2019�������Ƿ��֣�ֻ����Щ�ܽ������ijɷ�ѡ���Ե��ؽ�eFC��������߱��Ե�ʶ���������Ż��ij̶�ԶԶ������nFC���ݲ�����ͬ����ʱ�ı��֡��������������ȫ��ͬ��fMRI BOLD���ݣ�eFC���ݾ��и�ǿ�ĸ���ˮƽ��ָ��ʶ������������ע���������������类�Ե���ؾ����z-score��һ����Ҳ�����˱������뱻�Լ�ɨ�������Եľ��Բ��죨Finn���ˣ�2015����δ������Ҫ��һ���о������Ӹ��������ݼ�������ȵػ���ض�������Ϣ��
��Ȥ���ǣ������Ż�eFC�ĸ���ʶ�����������PC�����������������ݼ��еı���������ƥ�䡣��Щ�����֮ǰʹ��nFC���и���ʶ����о������Amico��Goñi��2018b�������ǵĽ������ʾ����һ�������г���һ���ز��rsfMRIɨ�裬�������Ƚ��ġ���ô��Ϊʲô�ڶ�ʶ�����������Ż�ʱ��PC�������뱻�Ե�������ƥ�䣿Ϊ�˽��������⣬���Ƿ��������ӣ�PC = 1-10���ͣ�PC = 11-100��ʶ��������PC��ϵ��������ѧ�ǶȽ�����eFCֵ��ɨ��Ϳ类�Ե������졣����100�����ɷ���Ψһ���г�����ֵ��PC�����⣬ֻ��PC��2��10���ض����Ե�ɨ����ʾ�����Ե�������ģʽ��һ�ֿ������ǣ���һ��PC��������ˮƽ��eFC���죬��DZ�ڵ���ˮƽ��eFC��������PC2��10�����ڽ����弶eFC���졣�����Ʋ⣬PC��������N-1��N=���Ե�����������Ϊÿ�����Զ�����ͨ�������Ĺ�����ȷ��N-1��PC����Щ�����һ��֤������������ת���㷨����PCA���о����Ƹ���ʶ������ʱ��eFC������һ���м�ֵ�ķ�����Ȼ����δ���Ĺ����б�Ҫ����PC�ľ�ȷ��������Ӧ̽��������ά���������ӷ�����CCA��Child, 1990, Thompson, 1984�����Ż�Idiff��
3.4 չ��
���ǵĽ��Ϊδ�����о��ṩ�������˷ܵĿ����ԡ����������ʹ����һ����ǰ�����ʶ��������Ȼ���������������ijЩ����¿��ܻ���������磬�����������Ա��ֳ���ˮƽ�����������ԣ���ʹ����ı��Ա��ֳ��ϲ�����������ԣ�Idiff��Ȼ����ȡ�ø�ֵ��Abbas, Amico,Svaldi, Tipnis, Duong-Tran, Liu, Rajapandian, Harezlak, Ances, Goñi, Abbas,Liu, Venkatesh, Amico, Harezlak, Kaplan, Ventresca, Pessoa, Amico, Goñi, 2018,Jalbrzikowski, Liu, Foran, Klei, Calabro, Roeder, Devlin, Luna, 2020����δ���Ĺ���Ӧ���о���������ʶ��������ܵ���������������������ϵ����I2C2����Shou���ˣ�2013����Discriminability��Bridgeford���ˣ�2020�������⣬δ���Ĺ���Ӧ��̽������ʶ��Ķ����������Yoo���ˣ�2019����
��Ӧͨ������ʶ��������������չ��ϵͳ���������еı仯�����ֹ���ʶ����������Դ���⡣���и�ˮƽʶ��������������ֳ����ԵĿ����ֲ��죨Xu���ˣ�2020�꣩���������һ����ʼ�վ��������ԣ�Jalbrzikowski���ˣ�2020b�������Ŵ�Ӱ�죨Demeter���ˣ�2020�꣩�����ڴ�����ģ���о��и߶�ʶ��������Bergmann���ˣ�2020�꣩���˽�ʶ�������ͻ������ӵ������Ե���Դ�������������˽���������ѧ�����Խ����Լ�������˥�Ϲ��̡�
����ѧϰ������Ӧ�ã�Demeter���ˣ�2020�꣩����ϸ��ֳ���ģʽ��Kumar���ˣ�2018�꣩���Լ�����fMRI�����Ŀ����ȣ�Tipnis���ˣ�2020�꣩�ѱ���������Ч���Ƹ���ʶ��������ֻ��ע��Щ����ȵ���߱��������Ե���Ԫ�أ�Sripada���ˣ�2020�꣩��ѡ���Ե�ʹ�ø������"�¼�"ʱ�����ؽ�eFC��������ǰ�Ĺ����и�����nFC��ʶ��������Esfahlani���ˣ�2020�꣩����Щ�������������ڼ������eFCʶ������������������ͼ�����Դ��δ�����о���Ҫ����ȵ�����eFC������fMRIɨ��ʱ��ͼ�����Դ�з���������������
3.5 ������
��eFC��ص�һ�������ǽ��������������ϵ������eFC�����е�ÿ�����������漰�ĸ��ڵ㣨��������-�������ӣ����ڴ��������£����������κ�һ����������֪ϵͳ�Dz����ܵġ��ڴˣ����DZ�������һ�������⣬����������eFC��ʶ�������в�����һ���ڵ���Ƴ����൱��200���ڵ�����е�199���ߣ���Ӱ�죬����ֻ���������Ե�һϵͳ�����߶ԡ���Ȼ��Щ������ͼ�����߶�λ������������δ���Ĺ����б�Ҫȷ��һ��ǿ��ķ�������eFCԪ���ݵ����Ե��ض�λ�á�
�ڶ��������ǹ���"����ʶ������"�IJ�����������ͬʱ�����˱����ںͱ��Լ�������ԡ�Ȼ�������dz���ʶ������������ָ�꣬�����FC-FC����Եĸ���ʶ�ȣ�Finn���ˣ�2015�꣩��ROC�������߹������������߾��ȣ�Jalbrzikowski���ˣ�2020a�����Լ���ͼ��Ƕ���ʾ�ж�ÿ������ʹ���������ķ���ģ�ͣ�Abbas���ˣ�2020a����������ˣ����ǻ���ʹ��Idiff���з�������Ϊ���ַ�����չ��һ�����е�ʶ����Finn���ˣ�2015����ͬʱ���ǵ��˲�ͬ����֮�乲����"��ͬ����"��Amico��Goñi��2018b����Ȼ������������ʶ�������ͱȽ�fMRI���ݵķ���ҲӦ�ñ�����Ϳ������Խ�һ���˽�������Ϊ���ĵ�FC�������ԡ�
���һ�������ǹ��ڹ������߾�������������ij������������ʹ��k-means�㷨������eFC�����ƶȽ�������Ϊһ��̶������ļ�Ⱥ�����ֹ�������Ⱥ�����ĺô��Ǽ���Ч�ʸߣ������þ�����������㡣���ھ������������кܶࣨFortunato��2010��Porter��Onnela��Mucha��2009��Sporns��Betzel��2016�������뿪�������㷨���������Ⱥ�����⣬��Ⱥ֮������߿�����Ϊ����ϵͳ֮����������Խ�һ���������칦�ܺ���Ϊ֮��Ĺ�����Jo���ˣ�2020����Ȼ�������ǵķ����ų��˼�Ⱥ֮������ߣ���רע�ڼ�Ⱥ�ڵ����ߡ�δ�����о�Ӧ�õ��鲻ͬ�����㷨��Ӱ�죬���о��������������������߶Ը�������Ӱ�졣
4 ���Ϻͷ���
4.1 ���ݼ�
The Midnight Scan Club��MSC�����ݼ���Gordon���ˣ�2017�꣩����10�������ˣ�Ů��ռ50%������=29.1��3.3����rsfMRI���������о��õ��˻�ʢ�ٴ�ѧҽѧԺ�����о�ίԱ��ͻ������ίԱ����������õ������б��Ե�֪��ͬ���顣ÿ�����Ե�12��ɨ�����ڲ�ͬʱ���ȡ�ġ�����ÿ�����ԣ�ʹ���ݶȻز�EPI���У�����ʱ��=30 min��TR=2200 ms��TE=27ms����ת��=90�㣩������10��rsfMRIɨ�裬ͬʱ�Ա��Խ����������Լ�ⳤʱ����۵����������������˯�������ͼ������3T������Trio�������ռ��ġ�
The Human Connectome Project��HCP�����ݼ���VanEssen���ˣ�2012�꣩���� ����100�������ij��걻�ԣ�Ů��ռ54%��ƽ������=29.11��3.67�����䷶Χ=22-36���ľ�Ϣ̬�������ݡ���Щ������������������ƻ������ġ�100 Unrelated Subjects(U100)����ѡ���ġ����о��õ��˻�ʢ�ٴ�ѧ�������ίԱ�����������������б��Ե�֪��ͬ���顣�����������ʱ����������Ĵ�15���ӵ�rsfMRIɨ�衣���ڳ��������ͼ��Ԥ�������̵���������������Glasser���˷��������ף�2013�����ҵ���ʹ���ݶȻز�EPI���вɼ�rsfMRI���ݣ�����ʱ��=14:33min��TR=720 ms��TE=33.1 ms����ת��=52�㣬����ͬ�����طֱ���Ϊ2 mm����Ƶ������=8�����������۲��̶���һ��ʮ�ּ��ϡ�ͼ�����ڴ���32ͨ��ͷ����Ȧ��3T������Connectome Skyra�������ռ��ġ�
4.2 ͼ��Ԥ����
4.2.1MSC��������Ԥ����
ʹ�û���Nipype 1.1.9��Gorgolewski���ˣ�2011����fMRIPrep 1.3.2��Esteban���ˣ�2017����MSC���ݼ��еĹ���ͼ�����Ԥ������fMRIPrep���ں���FSL, AFNI, freesurfer,ants��pipeline�������¶�fMRIPrepԤ�����������ǻ����������ַ���ģ�壬��������"������Ȩ��"��CCO������֤���ǡ�fMRIPrep���ڲ���������Nilearn 0.5.0��Abraham���ˣ�2014����ANTs 2.2.0��FreeSurfer6.0.1��FSL 5.0.9��AFNI v16.2.07�����ڸ�pipeline�ĸ���ϸ�ڣ���fMRIPrep�ĵ����빤�����̶�Ӧ�IJ��֡�
ÿ�����Ե�T1��Ȩ(T1w)ͼ��ʹ��N4BiasFieldCorrection(ANTS)��Avants, Epstein, Grossman, Gee, 2008, Tustison,Avants, Cook, Zheng, Egan, Yushkevich, Gee, 2010������ǿ�Ȳ�������У��������������������������T1w�ο���Ȼ��ʹ��antsBrainExtraction.sh��������Nipypeʵ���ǰ��룬ʹ��NKI��ΪĿ��ģ�塣ʹ��recon-all��Dale���ˣ�1999�꣩�ؽ����Ա��棬��ʹ��Mindboggle��Klein���ˣ�2017�꣩������֮ǰ���ƵĴ�����ģ���Ե���ANTs��FreeSurfer������Ƥ����ʷָʹ��T1w�����ģ����ȡ�Ĵ��Խ��з�������(antsRegistration)���ռ������ICBM 152�����ԷǶԳ�ģ��(2009c)��ʹ��FSL fast����ȡ��T1w�����Լ�Һ(CSF)������(WM)�ͻ���(GM)������֯�ָZhang���ˣ�2001����
ʹ��AFNI��3d Tshift�Թ������ݽ���ʱ���У����ʹ��FSL��mcflirt����ͷ��У����ͨ����ͬһ���ԵĹ���ͼ����й�����������ͼʧ��У��������antsRegistration��ʹ��ƽ����ͼģ������ǿ�ȷ�ת��T1wͼ��Ȼ����û��ڱ߽�Ĺ���������9�����ɶȣ�����Ӧ��T1w�����������˶�У���任����ʧ��У��Ť����BOLD-T1w�任��T1w-MNIģ��Ť��ͳһ��antsApplyTransforms��Lanczos��ֵ������Ӧ�á���������Ԥ�������̲�����BOLD��֡λ�ƣ�FD����DVARS������������ȫ���źţ�������������ӵ�ʱ�����С�FD��DVARS��Ϊÿ���������м���ģ�����ͨ��Nipypeʵ�֡�����ȫ���ź�����CSF��WM��ȫ����ģ����ȡ�ġ����о���ʹ�õ�ÿ��MSC���Ե�NIFTI����ļ���ѭ�ļ�����ģʽ��*_spaceT1w_descpreproc_bold.nii.gz��
4.2.2HCP��������Ԥ����
����Glasser���ˣ�2013������������HCP���ݼ��еĹ���ͼ���������С����Ԥ�����������֮����Щ���ݱ�У�����ݶ�ʧ����˶�ʧ�棬Ȼ��ͨ��һ��������ֵ��������Ӧ��T1��Ȩ��T1w��ͼ����롣����ݻ�����һ��У����ǿ��ƫ�����һ��Ϊ10,000��ƽ��ֵ��Ȼ���ݻ�Ͷ�䵽32k_fs_LR�����ų��쳣ֵ����ʹ�ö�ģ̬��������Robinson���ˣ�2014����һ�������ռ䡣���о���ʹ�õ�ÿ��HCP���ԵĽ��CIFTI�ļ���ѭ�ļ�����ģʽ��*_REST{1,2}_{LR,RL}_Atlas_MSMAll.dtseries.nii��
4.2.3 ͼ����������
��������MSC��HCP���ݼ��Ĺ���ͼ��������ʹ��fMRIPrep���Ӿ������MRIQC 0.15.1��Esteban���ˣ�2017������MSC�й���ͼ���������ͨ�����ۼ��MSC���ݵ�ȫ����Ұ���ǡ��ź�αӰ���Լ�����Ӧ�Ľ���ͼ�����ȷ������������е�ʱ����������Ҳ���������ӡ�
4.3 ��������Ԥ����
4.3.1 ����Ԥ����
һ��ּ���Ż�fMRI�źŵľֲ��ݶȺ�ȫ�������Բ����Ĺ��ܷ���������Schaefer���ˣ�2017����Schaefer200���������������Ƥ���ϵ�200��������Щ�ڵ�Ҳ��ӳ�䵽Yeo���������磨Thomas Yeo���ˣ�2011��������HCP���ݼ���Schaefer200��32k_fs_LR�ռ���CIFTI�ļ�����ʽ�����ṩ������MSC���ݼ���ʹ�ø�˹����������ͼ����Fischl���ˣ�2004������100������ص�HCP������ѵ������FreeSurfer��mris_ca_label������ÿ�����Զ���һ��Schaefer200��������Щ����������recon-all pipeline�м���ı����������ݸ���������ʺ���ģʽ����Ⱥ��ƽ��ͼ��ת�Ƶ�����ռ䡣���ַ���Ϊÿ�����Գ�����һ��T1w�ռ������Ϊ���빦������һ��ʹ�ã������IJ��ֱ�����ȡ����2 mm��T1w�ռ䡣������̿����ظ����������ֱ��ʵķ�������Schaefer100����
4.3.2 ��������Ԥ����
ÿ��Ԥ������BOLDͼ��ʹ��Nilearn��signal.clean����������ȥ���ơ���ͨ�˲���0.008-0.08Hz����Parkes�ȣ�2018��������ȥ���ͱ�����ȥ����ʱ���˲������Ļ��ӣ�Lindquist�ȣ�2019�������õĻ����ع飨Satterthwaite�ȣ�2013������6���˶�����ֵ��ƽ��CSF��ƽ��WF��ƽ��ȫ���źŵ�ʱ�����У���9���ع����ӵĵ������Լ���18���ƽ�������⣬����ÿ֡�����˶���ֵ��fMRIͼ��MSC=0.5 mm��֡��λ�ƣ�HCP=0.25 mm�ľ�����λ�ƣ�������һ����ֵ�ع����ӡ����ֻ��������ѱ�֤���Ǽ����˶����αӰ��һ�������Ч��ѡ��Parkes���ˣ�2018��������Ԥ�����ͻع�����Э�������ָ���ÿ���ڵ�IJв�ƽ��BOLDʱ�����С�
4.3.3 ����ͼ�۹���
ͨ����ȡ�ֲ�ʱ���������ݺ����ǵ�z-scores������eFC�����Ƕ�ÿ��ʱ����ֵ��z�仯������������Ȼ���������гɶԵ����������Ǽ������ǵ�z-scoresʱ�����е����������Ӧλ��Ԫ�صij˻����⽫�õ�"����ʱ������"����Ԫ�ر�ʾ���������֮���˲ʱ�������ķ��ȣ���������ʱ�����е�ƽ������������ȫ����Pearson���ϵ�����������ʱ�����ж�֮����м��㣬�������������ʱ�����еĹ����ϵ���������жԵı����ظ�ʱ������ͻ���һ����߾�����Ԫ�ر���һ��������[-1��1]��
4.3.4 ����ʶ������
�����������ʶ��������ָ�Ʒ����ǻ������¼��裬����ڲ�ͬ����֮�䣬�������Ե��������Ӧ����ñ��ԵIJ�ͬɨ���ģ���и�Ϊ���ơ�֮ǰ���о�ʹ�ô�ͳ���������飨Finn���ˣ�2015�꣩������ʹ��Ƥ��ѷ��ط�������һ�鱻�Ե�FC��ʹ��sample FC�ҵ����Ե�"Ŀ��"FC���Ϳ��ԶԸ������ǿ������ʶ��֮ǰ���������������ӵĸ��������о����������ؾ��루Venkatesh���ˣ�2020������ɨ����Ƥ��ѷ��أ�Amico��Goñi��2018b������Ȼ��ؾ��뷽��Ҳ�ṩ��ɨ��������ܽ��Դ�ʩ������������Amico��Goñi��2018b��������ָ�꣬��ָ�꿼����eFC��FC�����Э����ͱ�ƫ������������Ϊ����ʶ��������Idiff������Դ��"ʶ����������"��������FC֮�������ԣ�Pearson������ͨ����������ʶ��������Iself���Ҽ�ȥ����֮��������Ի�Iothers������Idiff����ʾΪʶ����������ĶԽ��ߺͷǶԽ���Ԫ�أ�ͼ1b����һ�鱻�ԵIJ���ʶ��������Idiff�������ܽ�Ϊ���¼��㣺
 ����ƽ�����������ƶȺ�ƽ�����Լ����ƶ���FCs�ϵIJ��졣���ݼ��еĽϸߵ�Idiff���и��ߵĸ���ʶ��������ʶ���������Ż�����Ϊ���Idiff��
����ƽ�����������ƶȺ�ƽ�����Լ����ƶ���FCs�ϵIJ��졣���ݼ��еĽϸߵ�Idiff���и��ߵĸ���ʶ��������ʶ���������Ż�����Ϊ���Idiff��
Ϊ�������ظ��Ժͷ�����Ӱ����������HCP���ݼ���100�������ı����ظ������˷�����Van Essen���ˣ�2012����HCP���ݼ�����ÿ�������ڲ�ͬ���ڵ�����ɨ��ʱ�ε��Ĵ�ɨ�衣����ÿ��ʱ�Σ����ǽ�����ɨ�裨�����Һʹ��ҵ������λ���룩������һ�����д����Ե�ʱ�����С����������������ʱ���������������������ƶ�Iself��ͨ������100����200���ڵ����ݼ��IJ���ʶ�������������˷���������Ӱ�죨ͼS1����
4.3.5 ͨ���ڵ���һ���ٴ��������ʶ������
����һ���У����������˼���Idiff�����̣�����һ����֪�������������뱻�Լ�ɨ�����������Եķ�����Amico��Goñi��2018a�����ڱ����У���ʹ������eFC���������ȣ����Dz����˴�eFC�ļ������Ƴ���Щ��������ٸ���ʶ���Idiff�����⣬���ǻ���������ʹ��ȫ��eFC��ȣ�ȥ���ض��Ĵ���ϵͳ�Ƿ�����Լ���Idiff��
eFC���߶ԵĹ�ͬǿ�Ⱥ�����֮���ֱ����ϵ��ij�̶ֳ��Ͽ�����һ������ij�����Ϊ��eFC��һ�����߶�����������  ����������ϡ�Ϊ�˱����������߶Ե�Ȩ�������߶�ǿ�ȳ����Թ�ϵ�ļ��裬�����ڹ���eFC����֮ǰ�����˽ڵ���һ�����ڹ���eFC֮ǰȥ��һ���ڵ��Ч����ͨ����ȫ��Idiff�м�ȥȥ��һ���ڵ��eFC��Idiff���������ͼ3a-b����
����������ϡ�Ϊ�˱����������߶Ե�Ȩ�������߶�ǿ�ȳ����Թ�ϵ�ļ��裬�����ڹ���eFC����֮ǰ�����˽ڵ���һ�����ڹ���eFC֮ǰȥ��һ���ڵ��Ч����ͨ����ȫ��Idiff�м�ȥȥ��һ���ڵ��eFC��Idiff���������ͼ3a-b����
������������ÿ�����Թ���ϵͳ��Ӱ�죬�Լ����ȥ����ϵͳ����eFC��õ�Idiff���졣������ǰ��ĵ����ڵ�ȥ������������ȥ���˵���ϵͳ��������ϵͳ�����нڵ㣩����ͨ����ȫ����Idiff��ȥ��һ������������Idiff��Ӱ�죨ͼ3c-d��������û�п��ƽڵ������IJ��죨������������200���ڵ㣬����ϵͳȥ���Ĵ�ԼΪ190���ڵ㣩����Ϊ�ڵ�������Idiff��Ӱ�컹�������
4.3.6 ��һϵͳ���߶Ե�ʶ������
�ڵ���һ���ĺô���ע�������ǣ�����eFC���ص����ԣ���ɾ���������漰�ض��ڵ��ϵͳ�����߶���Faskowitz���ˣ�2020������ˣ�������һ�ص㣬�����Բ��������ĵ�һϵͳ��Ӱ�졣Ϊ��ȷ����һϵͳ��Idiff��������ȡ��ֻ���������ض�ϵͳ�Ľڵ�����߶Բ�������Idiff�����Ƶķ�����Ӧ����nFC�����а�������nFC�Ľڵ�ԣ���Щ�ڵ�������Ե�һϵͳ�Ľڵ㡣��һϵͳ�Ľڵ����eFC�����߶Խ����˱Ƚϣ�Pearson����ԣ������⣬ʹ�����Ե�һϵͳ�����߶Եı��������Ծ��������ͼS3��
4.3.7 ʶ��������K-means�����㷨
�봫ͳ��nFC������ȣ�����ʹ�õ�eFC������гɷ�ά����ƽ������ȻeFC�ĸ�ά������������չʾFC��������ֱ����ʾ����ɷ�֮��Ĺ�ϵ������֮��Ĺ������������eFC����ijɷֽ��о�����һ�������ϵ���ս���������ķ�������δ֪������̽���Ļ�������������ˡ�Ϊ�˽��������Ⲣ��eFC���о��࣬����Ӧ����һ���������������eFC����ĵ�ά��ʽ���в�����
���ȣ�����Faskowitz���˵��о���Faskowitz�ȣ�2020�꣩�����Ƕ�ƽ��eFC����19900�� 19900�������������ֽ⣬��ƽ��eFC����������ɨ���eFC�����ƽ��ֵ���������������������ֵ��ص�ǰ50������������ͨ����ÿ�������������������ķ���Ԫ�أ���Щ�������������µ���Ϊ[-1,1]�����ڡ�Ȼ�������ñ���k-means�㷨��ŷ����þ�����������ŵ������������о��ࡣ���Ǹı�������������k����k=2��20����ÿ��ֵ���ظ������㷨250�Ρ����DZ�����������������������������������Եķ�����Ϊ�����Է�����
����ʹ��k-means��������Ϊ��Ⱥ����Ŀ��k=2��k=20����209����ͬ�ļ�Ⱥ������eFC����Ϊk��Ⱥ������������Ӧ��eFC����Ϊk����Ⱥ�ں�k(k-1)/2����Ⱥ������-������������顣���ǵ�Ŀ����������Щ�������������õ����ⲻͬ�ļ�Ⱥ��ϵͳ�������Idiff������ġ���Щ��������ͼS4�н�һ��������
Ϊ�ˣ����ǽ��������¼�����������ȣ�����ÿ�����飬������ȡÿ�����Ժ�ÿ��ɨ���Ԫ�أ�������ɶԵ������Ծ�������������ڵ�����-�������ӵ�Ȩ������صģ��Ϳ�����Ϊ����ɨ���DZ˴����Ƶġ�Ȼ������Ϊÿ�������������������������Щ��������ÿ�����������-�������ӵ�ƽ�����ͱ���Լ�ÿ������ϵͳ�ڷ����������������еĴ����̶ȡ������֮�������Ǵ���ƽ��eFC����ļ�Ⱥ�еó��ġ�ÿ����������˳ɶԵļ�Ⱥ֮�������-�������ӵļ��ϡ���������ɨ��ͱ��Ե�ÿ�������eFCԪ�ر�����������������eFCֵ��ƽ��ֵ�ͱ��Ȼ����ÿһ��k��Ⱥ�����Ǽ���ü�Ⱥ�����������ƽ�����ͱ���������ͨ��ϵͳ��ǩ������ÿ�������Ԫ�أ����Ƿ�����Щϵͳ��ǩ�������Idiff�йء�
����ѧ�ϣ���Щ��Ⱥ�����˲��ص�������Ⱥ�����Ƿ���Ҳ����ʹ��һЩ�������������㷨�����������㷨�������������е������ṹ��������Ϊһ�ֹ���ľ����㷨������ģ������Newman and Girvan, 2004����Infomap��Rosvall and Bergstrom, 2008����Ȼ�����ڴ˿��ǵ�ʵ���ԣ������ٵ�����ʱ�䣩������ʹ����k-means�㷨��
4.3.8 ���ɷַ���
���ɷַ�����PCA����һ�ֹ㷺ʹ�õĿ�����̽�����ݻ����ṹ��ͳ�Ʒ�����Jolliffe��2014����PCA��һ�����DZ����ر����Ĺ۲�����ת��Ϊһ���Ϊ���ɷֵ����Բ���ر�����Ȼ����Щ���ɷְ��ս������ݷ���Ӵ�С��˳������������Dz������ɷַ�����ֱ�ӶԱ�eFC��nFC��ʶ���������֣����Amico��Goñi��2018b���Ѿ�������̽����
���ȣ����ɷֵ����������ݼ��еĹ������������������ƥ�䡣���ݶ��壬�ֽ�PCA���Խ���������100%�ķ���Դ�PC=2��20��PC������͵ķ�����н������С������nFC��eFC����ؽ�Ϊ�������ijɷ������ĺ���������������ˮƽ����Ϣ�ڸ߷���ɷ��н��У�������ˮƽ����Ϣ���ڽϵͷ���ɷ��д�����������ؽ������У����ǰ��ս��ͷ���ĵݼ�˳���PC�����˼Ӻ͡���ÿ�μӷ��ؽ�ʱ��ÿ����������Ӿ����Ǹ���PC=1��N��ƽ���������������PC���ؽ��ġ�
�����������ǿ����˱���ɨ�������Ӱ�죬������Ӱ�챻�Ե���ɨ��ʱ�����������ͼ2a��b������MSC���ݼ��У����Ǵ�ÿ�����Ե�ʮ��ɨ�������ѡ��������ΪPCA������Idiff���ֵ���в�����ɨ�裬����100�ε�������eFC��nFC�У��������ݼ��еı���������ƥ���10��PC�Ż�Idiff��ͬʱ�����Ǵ�100��������������10�������������Ƿ�Idiff�����Ż������������������DZ��Ա�������HCP���ݼ��У����Ǵ�100�����������ѡ����10�����ԣ�ÿ������������ɨ�衣��100�ε����е�ÿһ�Σ�Ϊÿ��PC��Idiff�����˿��ӻ���ͼ��ͼS7c-d�������ǻ�ͨ��ƥ��HCP���ݼ���ʱ��㣨2400��ʱ��㣩��MSC���ݼ���ʱ��㣨800��ʱ��㣻ͼS7f��������������ɨ��ʱ���Ӱ�졣����ÿ�����ԣ�����ֻ�������Һʹ��ҵ����ɨ���е�400��ʱ�������������һ��800��ʱ����ɨ�衣���仰˵������ɨ����м䲿�ֱ�����������Ϊÿ�����Դ���һ��800��ʱ���ĵ�һɨ�����ݡ�ͨ�����ӵ�ɨ�裬���ǽ�����������ͼS7c�ķ������������������HCP���ݼ���100�����ԣ�ÿ����������ɨ�裻ͼS7e��������PC�ؽ����Idiff��
��MSC��HCP���ݼ��У����Ƿ��ֱ��Ե����������ɷֵ�������ƥ�䣬���ɷֵ�Idiff���ؽ���eFC��nFC�����������ġ�Ϊ��ȷ����һ�����DZ���������أ����Ƕ�ÿ��ɨ���ÿ��PCϵ�������˷ֽ⣬ͼS9��ͼS10��ͼS11��ͼS12������PC��2��10��ÿ�����Ե�ϵ�����������Ե�ϵ�������˲��ԣ�t �C test with Bonferroni-correction����
����ԭ�ļ��������������˼Ӱ�Ƽ��ţ�siyingyxf��18983979082��ȡ,���˼Ӱ�γ̼��������ȤҲ�ɼӴ��ź���ѯ����˼Ӱ�ṩ����������ط�������ҪҲ�����Ӵ��ź���Ⱥ��ԭ��Ҳ����Ⱥ�����������ǵĽ���������о��а����������ת��֧���Լ����½ǵ��һ���ڿ����Ƕ�˼Ӱ�Ƽ���֧�֣���л��

��ɨ����߳���ѡ��ʶ���ע˼Ӱ
�dz���лת��֧�����Ƽ�
��ӭ���˼Ӱ�����ݴ���ҵ�γ̽��ܡ�����ֱ�ӵ���������ּ������˼Ӱ�Ƽ����еĿγ̣���ӭ�����ź�siyingyxf��18983979082������ѯ�����пγ̾����ű��������������ǻ��һʱ����ϵ���������ѱ���ѧԱ������˴ţ�
�Ϻ���
����ʮһ��Ź������������ݴ����ࣨ�Ϻ���10.28-11.2��
����ʮ�Ž�Ź�����Ӱ������ࣨ�Ϻ���11.4-9��
��ʮ�Ľ�����̬���ܴŹ������ݴ����ࣨ�Ϻ���11.30-12.5��
���죺
����ʮ��Ź�����Ӱ������ࣨ���죬10.22-27��
�ڶ�ʮ�˽���ɢ�������ݴ����ࣨ���죬11.5-10��
��������ɢ�Ź��������߰ࣨ���죬11.17-22��
�ڶ�ʮ����Ź�����Ӱ��ṹ�ࣨ���죬11.27-12.2��
�Ͼ���
����ʮ����Ź������������ݴ����ࣨ�Ͼ���10.16-21��
�ڶ�ʮ����Ź�����Ӱ��ṹ�ࣨ�Ͼ���10.24-29��
����ʮһ��Ź�����Ӱ������ࣨ�Ͼ���11.12-17��
�ڶ�ʮ�Ž���ɢ�������ݴ����ࣨ�Ͼ���11.19-24��
������
��ʮһ��Ź���ASL������������ǣ����ݴ����ࣨ������11.3-6��
����ʮ����Ź�����Ӱ������ࣨ������11.9-14��
������Ӱ����ѧ�ࣨ������11.25-30��
�����R����ͳ�ưࣨ������11.16-20��
�Ե缰���⡢�۶���
���죺
�ڶ�ʮ�߽��Ե����ݴ������Űࣨ���죬10.28-11.2��
�Ͼ���
������Ե����ѧϰ���ݴ����ࣨMatlab�汾���Ͼ���11.3-8��
�Ϻ���
����ʮ�����Ե����ݴ����м��ࣨ�Ϻ���11.13-18��
�ڶ�ʮ�˽��Ե����ݴ������Űࣨ�Ϻ���11.20-25��
���£��ڶ�ʮ���������Թ������ݴ����ࣨ�Ϻ���12.7-12��
������
���£���ʮ�����۶����ݴ����ࣨ������10.26-31��
���ݴ���ҵ����ܣ�
˼Ӱ�Ƽ����ܴŹ���(fMRI)���ݴ���ҵ��
˼Ӱ�Ƽ���ɢ��Ȩ����DWI/dMRI�����ݴ���
˼Ӱ�Ƽ��Խṹ�Ź����������ݴ���ҵ����T1)
˼Ӱ�Ƽ����������У�QSM)���ݴ���ҵ��
˼Ӱ�Ƽ������ද���С����Ӱ�����ݴ���ҵ��
˼Ӱ�Ƽ��鳤�ද��fMRI����ҵ��
˼Ӱ���ݴ���ҵ������ASL���ݴ���
˼Ӱ�Ƽ���Ӱ�����ѧϰ���ݴ���ҵ�����
˼Ӱ�Ƽ������Ⱥ����ҵ��
˼Ӱ�Ƽ�EEG/ERP���ݴ���ҵ��
˼Ӱ�Ƽ��������Թ������ݴ�������
˼Ӱ�Ƽ��Ե����ѧϰ���ݴ���ҵ��
˼Ӱ���ݴ������������Դ�ͼ��MEG�����ݴ���
˼Ӱ�Ƽ��۶����ݴ�������
��Ƹ����Ʒ��
˼Ӱ�Ƽ���Ƹ���ݴ�������ʦ ���Ϻ����������Ͼ������죩
BIOSEMI�Ե�ϵͳ����
Ŀ��ʽ���ܴŹ���̼�ϵͳ����