我从小就做眼动数据处理,,,,
统计检验是当前所有定量分析研究所必经的途径,尽管在今天我们已经有大量不同的统计方法来完成与我们的数据特征相符合的统计检验,但几乎所有的分析都建立在重要的基本假设之上。如果不注意这些基础,研究人员可能会无意中报告错误或不准确的结果。但是即便是在严苛的实验室研究中,与假设检验的统计前提存在偏差的数据所带来的影响也都会在一定程度提升一类错误(即假阳性)的发生率或者提升二类错误(即假阴性)的发生率(Jason
W. Osborne,2011,P4)。相关研究已经证明了这一点,在化学和农业公司以及贝尔电话实验室等研究实验室工作的研究人员通常是应用统计学家,他们在早期关于统计“稳定性”的研究多次体现出数据的“清洁度”的重要性。而在数据可能更混乱的社会科学领域,这一问题可能显得更为严重(丝毫没有觉得社会科学领域有问题哈,这可不是我说的,引自前一个文献)。
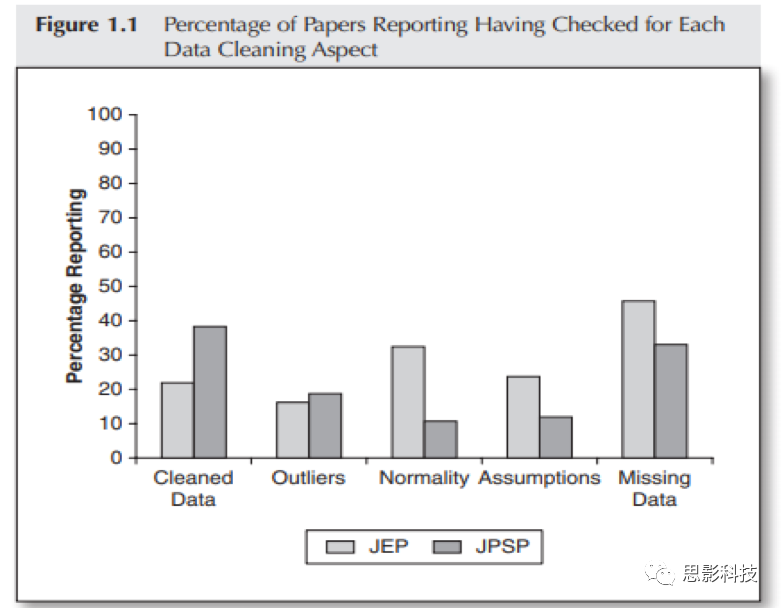
图1 以往文献中报告了数据清理细节的文献的占比图注解:(Osborne,
etal.,2011;这篇来自APA的文章研究了以往文献中报告了数据清理的内容和细节的文章,结果显现出进行过数据清洗的文献仅仅在22%―38%之间,而这些内容其实是定量方法研究中要报道的基本问题,可见这一问题在当今科学研究中仍旧是一个严峻的问题)
因为,一些统计学家将“适度偏差”视为完全不重要的、与完全正态性和完全方差相等的数学模型的微小偏差(比如T检验的提出者就声称这种方法对于符合正态样本或只有一些正态性偏差的小样本量的数据也能体现出鲁棒性的统计能力)。但是,社会科学家很少看到这样的研究争论,同时,他们也很难获取像在这些环境中产生的数据那样干净的数据。而眼动数据在这类不干净的数据中显得更为扎眼。没图没真相,带你feel一下眼动数据都会长什么样。
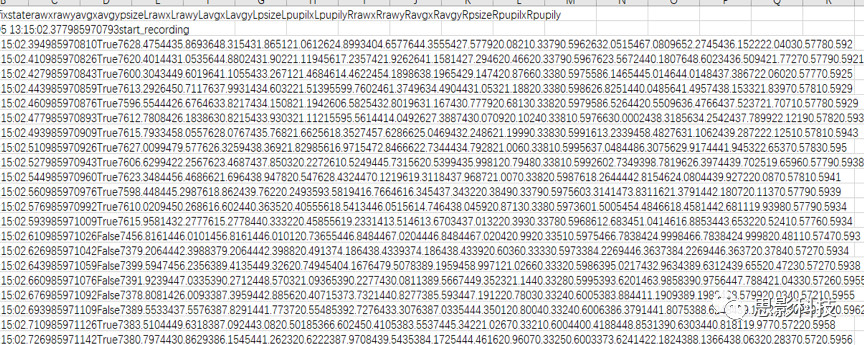
图2 这是一个采样点的数据,乱到你绝望,EXCEL甚至无法帮你进行基本的行列处理,并对你产生抵触心理。可能你会说,我用的是大厂家的数据的,我的后端输出非常的棒,我导出的注视点的数据整洁到可以直接分析,少年,我只能说年轻人毕竟还是too young。同样还是赤裸裸的真相展现给你。
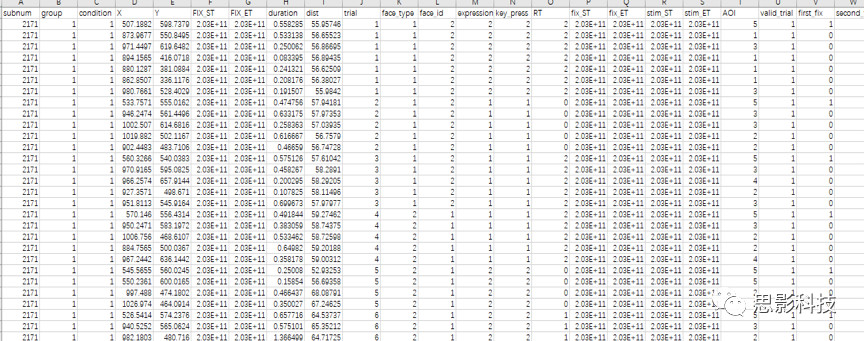
图3 这是一个相当整洁的注视点数据(实际上你导出的注视点数据要比这个还要杂乱很多),你可以看到你的数据整齐有序的排列在你的Excel里,但是这个数据有26列,有2000多行,有些变量是无用变量(即你统计的时候用不到)而有些变量不是按照你想象的那样产生的,例如一个被试如此多的注视点,有些注视点落在了你并不感兴趣的区域等等。

眼动是心理科学研究中重要的手段,通过记录和分析人的眼动数据可以来推断其心理过程。眼动仪则是我们的研究中用来实现这一研究过程的重要仪器,其采集所得的数据是我们进行定量分析的基础。而不同的眼动仪器导出的数据格式千差万别,有些仪器简陋到只能导出如文章图2那样混杂的采样点数据,有些仪器能量大很多(高投入,高产出,你懂的),可以导出更干净的注视点数据,但是即便是这样,眼动数据由于很高的采样率(或大量的注视点变化)的特性,导致你所得到的数据中一个trial(即一个刺激)也会得到很多个数据(注视点数据的量相对于采样点数据会少不少)。在这样的情况下,即使是一个被试的数据,一个实验做完,你所面对的数据量和数据的复杂程度也会让你想问自己:当初为什么我不做脑电或者fMRI作为课题?
那么我们在面对这样的数据时,该怎么办呢?答案只有一个――数据清洗!
那么什么是数据清洗呢?
其实,数据清洗并没有一个严格的定义,从广义来讲,对杂乱无章的数据按照一定的数据结构进行整理,然后对缺失值、异常值进行处理,使得原始数据更加符合你的假设检验的要求的过程就是数据清洗。但是,在这里我想引用著名的Vardeman & Morris(2003, p. 26)给出的对于假设检验中数据是否符合统计方法的前提要求对于研究重要性的观点:你必须完全理解你的假设说了什么,它们意味着什么。除非您真正理解此断言在您对其的应用中的上下文中的含义和限制,否则不能声称由于该方法的鲁棒性,通常的假设是可以接受的。你绝对不能使用任何统计方法而没有意识到你是在含蓄地做假设,你的结果的有效性永远不会超过其中最值得怀疑的那些。

图5 原文奉上,以防出现翻译的理解偏差影响了您的阅读体验
这样的观点在现今研究中受到越来越多的研究者的支持。而数据清洗的过程不仅仅是让你的数据更加符合你要使用的统计方法的假设前提,更是一个你了解自己的数据的每一个细节的过程。在眼动研究中,这一点尤为重要。那么数据清洗的步骤是什么?数据清洗过程中需要遵循的原则有哪些?什么样的工具可以更好的完成数据清洗?接下来就让我们仔细了解一下。(问号三连)
在数据清洗过程中,最重要的是建立自己的数据清洗的思路,在建立这个思路的过程中,首先就是要明晰数据清洗过程要遵循的一些基本原则。这样,在数据清洗中就可以做到有据可依。从目的来看,数据清洗的最基本原则是得到高质量的数据。数据质量往往会涉及许多因素,它们包括:准确率、完整性、一致性、时效性、可信性和可解释性。因此,在具体的数据清洗过程中,你要依据这些基本的原则来对你已经有的眼动数据进行“匹配”式的对应检查,看看你的数据是否是一个高质量的数据从而能够用来进一步的分析(很明显,导出来的原始数据基本质量都难以达到这些要求,你可以拿出自己的数据对着这几条原则来比照下哦)。
其次是熟悉自己的原始数据。你必须明确自己目前得到的眼动数据是什么样的?有什么样的特点?例如你的数据是注视点数据还是采样点数据;你的数据是已经有分隔符的数据还是连分隔符都没有;你的数据中多少行,多少列,每一列代表的是什么因素或者变量等等。这些都是需要你在数据清洗前必须要了解的步骤。
有句俗话叫一个萝卜一个坑。如果把你的数据比作萝卜田,那杂乱的萝卜田可能主要遇到以下三种问题:有的坑里没萝卜(缺失值);有的坑里的萝卜蔫了或者萝卜长的跟树一样高(异常值);白萝卜田里种了胡萝卜或者西瓜(数据不一致)。
了解到这些问题后,你就要开始对你的萝卜田进行修整(数据清洗)了。一般来说这样几个方面:拔草,耕田,施肥,喷农药,上大棚(不好意思,拿错课本了,这是临沂地区大葱(思影工程师大星的日常水果)种植概要)
第一个部分就是对缺失值的处理。缺失值的处理按照这张图片(图6)中所显示的原则来做。一般来说,我们可以通过一些方法来处理缺失值,常见的方法有:
忽略元组的方法(即置为空,也就是说把坑留着);
人工填写缺失值(自己挑萝卜栽);
将缺失值用属性相同的常量进行填充(栽批发的萝卜);
使用该数据周围的数据进行插值(拿和周围坑里的萝卜差不多的萝卜栽);
使用给定数据的同一类所有样本的均值或者中位数进行填充(拿和这块田所有萝卜差不多的萝卜栽);
使用回归、贝叶斯等方法基于推理或决策树方法来填充(去图书馆翻《阅禅与萝卜的艺术思想碰撞》,用知识来挑萝卜,人工智能种植萝卜)。
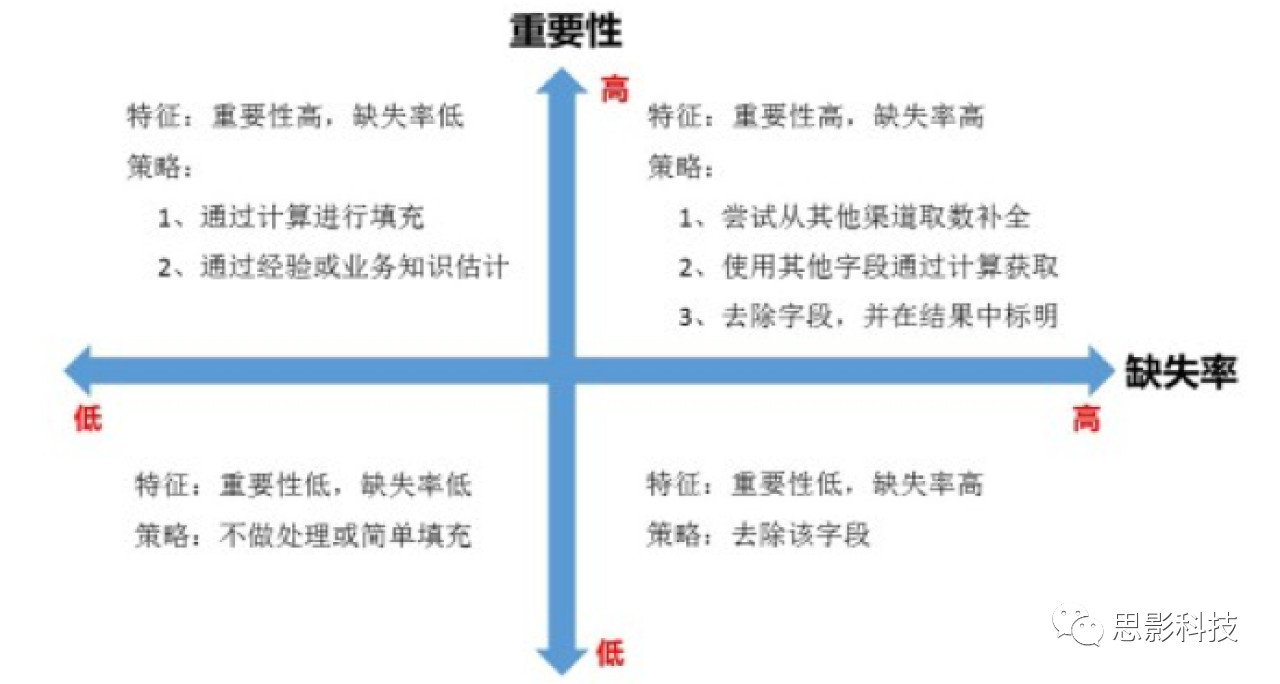
图6 缺失值处理的基本方法
第二个部分是对异常值的处理。异常值是指样本中的个别值,其数值明显偏离它(或他们)所属样本的其余观测值。对于异常值的处理往往通过:分箱、回归或者离群点分析的方法来实现(也就是先通过一系列手段辨别哪个萝卜是蔫的或者发疯生长长得像树一样的,再参考第一部分用新的正常的萝卜来取代它),不同的方法有其各自的特性和优缺点,选择何种方法往往是由数据清洗者(It is you ,my dear friend)来决定的。
图7 一种离群值分析方法
第三个部分是纠正数据中的不一致。数据中的不一致往往指的是格式差异导致的问题,例如对日期信息记载的不同格式会导致你在数据导入或者数据整理过程中出现很多问题,比如导入Excel报错等问题(即你想要的是亩产2万8的杂交白萝卜,种下去的苗是胡萝卜苗)。在眼动数据中,对于时间的记录是有不同的方式的,因此这样的问题出现的频率并不低。对于格式不一致的数据,我们处理的目的是将一个数据表中的数据的格式一致化,方法很多,但是灵活的进行处理可以带来时间上的大量节省。例如使用R进行处理(这就是萝卜魔仙的巴拉啦仙女棒,魔棒一挥,胡萝卜全变白萝卜)。
到这里,你的萝卜田,啊不,数据已经按照行列被整理的整整齐齐了,但是,你以为到这里就万事大吉了吗?当你看到这个问号的时候,就应该明白,事情远没有这样的简单。数据清洗除了让自己的数据整齐以外,还需要让你能够更好的进行后续的统计分析。因此,你的思路到了这里就要明确自己后续的数据分析及统计检验的思路了。在这个过程中,你要开始明晰后续的统计分析要用到哪些变量(将你不需要的变量数据删除,来降低数据表的复杂度并提升),不同的变量属于什么样的变量类型(防止将数字代表的分类变量进行计数统计,例如用“1”代表男这样的操作,一定要记下来)。当你把自己的数据能够清洗到这样的程度后,你的后续统计检验才能够顺顺利利的进行。
那么,我们还剩下最后一个问题,我们该用什么方法来进行数据清洗呢?我们要知道,眼动数据往往是几千行的,使用Excel和SPSS等界面方式来进行数据清洗是必然受到你的屏幕大小的限制的,你会不得已一直从左拖到右、再从上拖得下,当然了还得从右边回到左边,从下边回到上边。你可能会被这样的上上下下、左左右右逼到奔溃。那么,该用什么方法呢?看下图:

是的,没错,就是堪称“统计学界劳斯莱斯”的R语言。我知道你肯定最想问的是,眼动的数据清洗看起来这么复杂,我到底该去哪里学习?怎么学习呢?朋友,来,点击这里:
第五届眼动数据处理班
整整三天的用R处理眼动数据,带你从入门到高端,正可谓我在wow怀旧服里经常在世界频道喊的话:15年经验,T3毕业老法师代刷血色,走位风骚,意识一流,200g/hour,童叟无欺,位置有限,让你躺着升级。

关注吧,推荐吧,真爱,真爱
饭圈大佬强力推荐,二次元最爱,宅男看剧下饭利器
欢迎浏览思影的其他课程以及数据处理业务介绍。(别问,happy的挨个点击就到位了):
第十六届脑电数据处理班(中等难度)
第五届脑电数据处理入门班(南京)
第五届脑电信号数据处理提高班(疯狂的电脑)
第十八届脑电数据处理中级班(南京)
第十七届脑电数据处理班(重庆)
第五届眼动数据处理班(重庆)
第六届近红外脑功能数据处理班(上海)
第二十三届功能磁共振数据处理基础班(入门级别)
第十二届磁共振脑网络数据处理班(满难的,需要基础)
第十届磁共振弥散张量成像数据处理班(入门到高端,all in one)
第一届弥散磁共振成像数据处理提高班(有十层楼那么高)
第八届磁共振脑影像结构班(南京)
第八届脑影像机器学习班(高端,需要基础班打底)
第五届任务态fMRI专题班(南京)
第二十二届功能磁共振数据处理基础班(重庆)
第七届脑影像机器学习班(重庆)
第六届磁共振ASL(动脉自旋标记)数据处理班
第五届小动物磁共振脑影像数据处理班(重庆)
第二十四届磁共振脑影像基础班(重庆)
思影数据处理业务一:功能磁共振(fMRI)
思影数据处理业务二:结构磁共振成像(sMRI)与DTI
思影数据处理业务三:ASL数据处理
思影数据处理业务四:EEG/ERP数据处理
思影数据处理服务五:近红外脑功能数据处理
思影数据处理服务六:脑磁图(MEG)数据处理
招聘:脑影像数据处理工程师(mc开团,来无需求打手)